Spusťte zpracování dat pomocí Kafka a Spark
Zpracování velkých objemů dat: Výzva moderních organizací
Zpracování rozsáhlých dat představuje jednu z nejnáročnějších úloh, s nimiž se dnešní organizace potýkají. Tato komplexnost se dále stupňuje, když se jedná o zpracování obrovských objemů dat v reálném čase.
V tomto článku se podíváme na to, co přesně zpracování velkých dat znamená, jakým způsobem se provádí, a detailněji prozkoumáme dva z nejznámějších nástrojů pro zpracování dat: Apache Kafka a Spark.
Co je zpracování dat a jak probíhá?
Zpracování dat lze definovat jako jakoukoli operaci nebo soubor operací prováděných s daty, ať už automatizovaně, nebo manuálně. Můžeme si to představit jako proces shromažďování, třídění a organizování informací tak, aby byly logicky uspořádány a snadno interpretovatelné.
Když například uživatel vyhledává v databázi a získává výsledky, je to právě zpracování dat, které mu poskytuje potřebné informace. Výsledky, které se objeví po vyhledávání, jsou produktem zpracování dat. Z tohoto důvodu se informační technologie do značné míry zaměřují na efektivní zpracování dat.
Dříve se zpracování dat realizovalo prostřednictvím jednoduššího softwaru. S příchodem konceptu Big Data se však situace změnila. Big Data zahrnují objemy informací, které mohou dosahovat stovek terabajtů nebo dokonce petabajtů.
Navíc jsou tato data neustále aktualizována. Příkladem mohou být informace z kontaktních center, sociálních sítí, obchodní data z burz a podobně. Taková data se někdy označují také jako datové toky – kontinuální a nekontrolovaný proud informací. Jejich charakteristickým rysem je, že nemají jasně definované hranice, a nelze tedy přesně určit, kdy datový tok začíná nebo končí.
Zpracování dat probíhá ihned po jejich doručení na určené místo. Tento přístup se někdy označuje jako zpracování v reálném čase nebo online zpracování. Existuje i odlišný přístup, blokové, dávkové nebo offline zpracování, kdy se data zpracovávají v blocích v časových oknech o délce hodin nebo dní. Dávkové zpracování je často proces spouštěný přes noc, který konsoliduje data za daný den. V některých případech však i časová okna v délce týdnů či měsíců vytvářejí již zastaralé zprávy.
Nejlepší platformy pro zpracování velkých dat pomocí streamování jsou založeny na open-source technologiích, jako jsou Kafka a Spark, které se navzájem doplňují a umožňují využití dalších nástrojů. To vede k jejich rychlejšímu rozvoji a širšímu spektru aplikací. Díky tomu jsou datové toky přijímány z různých zdrojů proměnlivou rychlostí a bez přerušení.
Nyní se podíváme na dva z nejvýznamnějších nástrojů pro zpracování dat a porovnáme je:
Apache Kafka
Apache Kafka je systém pro zasílání zpráv, který umožňuje vytvářet streamovací aplikace s kontinuálním tokem dat. Kafka, původně vyvinutá společností LinkedIn, je založena na principu logu. Log je základní formou úložiště, kde se každá nová informace přidává na konec souboru.

Kafka je jedním z nejvhodnějších řešení pro velká data, a to zejména díky své vysoké propustnosti. S Apache Kafka je dokonce možné transformovat dávkové zpracování do režimu reálného času.
Apache Kafka je systém zasílání zpráv typu "publikovat-odebírat", kde aplikace publikuje zprávy a aplikace, která se přihlásí k odběru, tyto zprávy přijímá. Doba mezi publikací a přijetím zprávy se může pohybovat v milisekundách, díky čemuž má Kafka nízkou latenci.
Jak Kafka pracuje
Architektura Apache Kafka zahrnuje producenty, spotřebitele a samotný cluster. Producentem je jakákoli aplikace, která publikuje zprávy do clusteru. Spotřebitelem je jakákoli aplikace, která zprávy z Kafky přijímá. Cluster Kafka je sada uzlů, které společně tvoří jednu instanci služby zasílání zpráv.
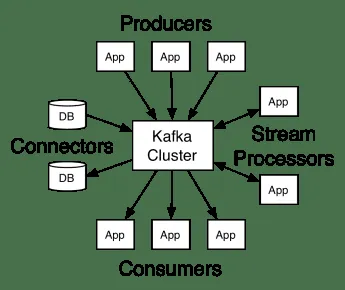
Kafka cluster se skládá z několika brokerů. Broker je Kafka server, který přijímá zprávy od producentů a ukládá je na disk. Každý broker spravuje seznam témat, a každé téma je rozděleno do několika oddílů.
Po přijetí zpráv broker odesílá zprávy registrovaným spotřebitelům pro každé téma.
Nastavení Apache Kafka spravuje Apache Zookeeper, který ukládá metadata clusteru, jako jsou umístění oddílů, seznam názvů, seznam témat a dostupné uzly. Zookeeper tedy zajišťuje synchronizaci mezi různými prvky clusteru.
Zookeeper je klíčový, protože Kafka je distribuovaný systém, což znamená, že zápis i čtení provádí více klientů současně. Pokud dojde k chybě, Zookeeper vybere náhradu a obnoví provoz.
Případy použití
Kafka se stala populární zejména díky svému využití jako nástroj pro zasílání zpráv, ale její všestrannost přesahuje tyto hranice a lze ji využít v mnoha různých scénářích, jak uvádějí příklady níže.
Zasílání zpráv
Asynchronní forma komunikace, která odděluje komunikující strany. V tomto modelu jedna strana odesílá data jako zprávu Kafce, která je později spotřebována jinou aplikací.
Sledování aktivity
Umožňuje ukládání a zpracování dat sledujících interakce uživatelů s webem, jako jsou zobrazení stránek, kliknutí, zadávání dat atd. Tento typ aktivity obvykle generuje obrovské objemy dat.
Metriky
Zahrnuje agregaci dat a statistik z různých zdrojů za účelem vytvoření centralizované zprávy.
Agregace protokolů
Umožňuje centrální agregaci a ukládání souborů protokolů z různých systémů.
Zpracování streamu
Zpracování datových proudů se skládá z několika fází, kde jsou nezpracovaná data čtena z témat a agregována, obohacována nebo transformována do jiných témat.
Pro podporu těchto funkcí platforma nabízí tři klíčová API:
- Streams API: Funguje jako procesor datových proudů, který spotřebovává data z jednoho tématu, transformuje je a zapisuje do jiného.
- Connectors API: Umožňuje připojení témat ke stávajícím systémům, jako jsou relační databáze.
- API pro producenty a spotřebitele: Umožňuje aplikacím publikovat a využívat data Kafka.
Výhody
Replikované, rozdělené a uspořádané
Zprávy v Kafka jsou replikovány napříč oddíly v rámci uzlů clusteru v pořadí, v jakém přicházejí, čímž je zajištěna bezpečnost a rychlost doručení.
Transformace dat
S Apache Kafka je možné transformovat dávkové zpracování do reálného času pomocí dávkového API ETL streamů.
Sekvenční přístup k disku
Apache Kafka uchovává zprávy na disku, nikoli v paměti, což je překvapivě rychlejší. Přístup do paměti je obecně rychlejší, zvláště pokud jde o data uložená v náhodných místech v paměti. Nicméně Kafka využívá sekvenční přístup, a v tomto případě je disk efektivnější.
Apache Spark
Apache Spark je výpočetní stroj pro velká data a sada knihoven pro paralelní zpracování dat napříč clustery. Spark je evolucí Hadoopu a paradigmatu programování Map-Reduce. Díky efektivnímu využití paměti, kdy se data během zpracování neuchovávají na discích, může být až 100x rychlejší.

Spark je organizován na třech úrovních:
- Nízkoúrovňová API: Tato úroveň obsahuje základní funkce pro spouštění úloh a další funkce, které vyžadují ostatní komponenty. Důležité jsou i funkce pro správu zabezpečení, sítě, plánování a logického přístupu k souborovým systémům HDFS, GlusterFS, Amazon S3 a dalším.
- Strukturovaná API: Tato úroveň se zabývá manipulací s daty prostřednictvím DataSets nebo DataFrames, které lze číst z formátů jako Hive, Parquet, JSON a dalších. S pomocí SparkSQL (API, které umožňuje psát dotazy v SQL) můžeme data manipulovat dle potřeby.
- Vysoká úroveň: Na nejvyšší úrovni se nachází ekosystém Spark s různými knihovnami, včetně Spark Streaming, Spark MLlib a Spark GraphX. Tyto knihovny zajišťují příjem streamovaných dat a související procesy, jako je obnova po havárii, vytváření a ověřování klasických modelů strojového učení a práce s grafy a algoritmy.
Jak Spark pracuje
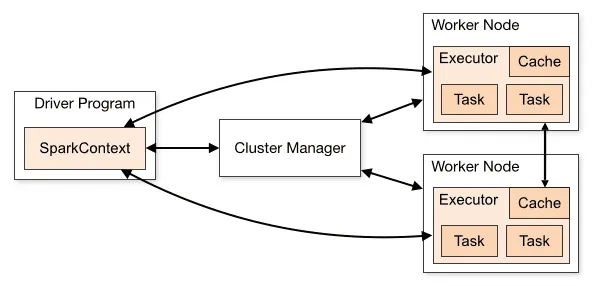
Architektura aplikace Spark se skládá ze tří hlavních částí:
Driver Program: Je zodpovědný za koordinaci a řízení provádění zpracování dat.
Cluster Manager: Jedná se o komponentu, která spravuje různé stroje v clusteru. Je potřeba pouze v případě, že Spark běží v distribuovaném režimu.
Pracovní uzly: Jedná se o stroje, které provádějí úkoly zadané programem. Pokud je Spark spuštěn lokálně na vašem počítači, bude plnit roli Driver Program i Workers. Tento způsob provozování Sparku se nazývá Standalone.
Kód pro Spark lze psát v mnoha různých jazycích. Konzole Spark s názvem Spark Shell je interaktivní a vhodná pro učení a průzkum dat.
Takzvaná aplikace Spark se skládá z jedné nebo více úloh (Jobs), což umožňuje podporu rozsáhlého zpracování dat.
Spark má dva režimy spouštění:
- Klient: Ovladač běží přímo na klientovi a nevyužívá správce prostředků.
- Cluster: Ovladač je spuštěn na hlavním serveru aplikace prostřednictvím Správce prostředků. Pokud se klient v tomto režimu odpojí, aplikace bude nadále běžet.
Je nutné používat Spark správně, aby služby jako Resource Manager dokázaly identifikovat potřeby jednotlivých spuštění a zajistily optimální výkon. Vývojář by měl znát nejlepší způsob, jak spouštět své úlohy Spark, strukturovat prováděné volání, a může si strukturovat a konfigurovat spouštěcí nástroje Spark dle vlastních požadavků.
Úlohy Spark primárně využívají paměť, proto je běžné upravovat konfigurační hodnoty Spark pro spouštěče pracovních uzlů. V závislosti na zatížení Sparku lze zjistit, že určitá nestandardní konfigurace poskytuje optimálnější výsledky. Proto lze provést srovnávací testy mezi různými dostupnými možnostmi konfigurace a výchozí konfigurací Spark.
Případy použití
Apache Spark pomáhá při zpracování obrovského množství dat, ať už se jedná o data v reálném čase nebo archivovaná, strukturovaná nebo nestrukturovaná. Níže jsou uvedeny některé z jeho oblíbených případů použití.
Obohacování dat
Společnosti často kombinují historická data o zákaznících s daty o chování v reálném čase. Spark může pomoci vybudovat kontinuální ETL kanál pro převod nestrukturovaných dat událostí na strukturovaná data.
Detekce spouštěcích událostí
Spark Streaming umožňuje rychlou detekci a reakci na neobvyklé nebo podezřelé chování, které by mohlo naznačovat potenciální problém nebo podvod.
Komplexní analýza dat relací
S pomocí Spark Streaming lze seskupovat a analyzovat události spojené s relací uživatele, jako jsou aktivity po přihlášení do aplikace. Tyto informace lze také průběžně využívat pro aktualizaci modelů strojového učení.
Výhody
Iterativní zpracování
Pokud je potřeba zpracovávat data opakovaně, pružné distribuované datové sady Spark (RDD) umožňují provádět více operací mapování v paměti, aniž by bylo nutné ukládat dočasné výsledky na disk.
Zpracování grafů
Výpočetní model Spark s API GraphX je ideální pro iterativní výpočty, které jsou typické pro zpracování grafů.
Strojové učení
Spark nabízí knihovnu MLlib s vestavěnými algoritmy strojového učení, které také běží v paměti.
Kafka vs. Spark
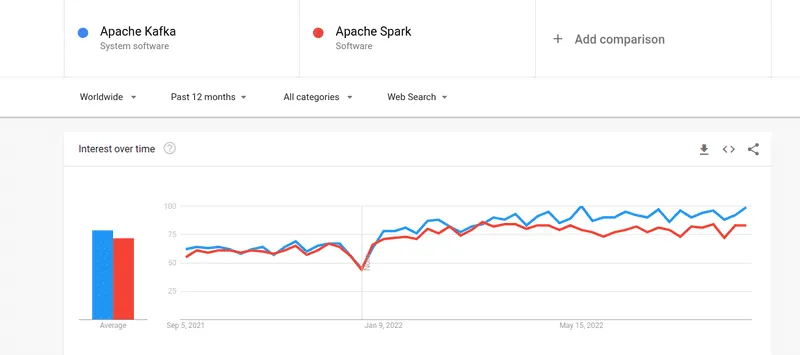
Přestože se zájem o Kafku i Spark blíží, existují mezi nimi některé zásadní rozdíly. Podívejme se na ně.
#1. Zpracování dat
Kafka slouží jako nástroj pro streamování a ukládání dat v reálném čase a je zodpovědná za přenos dat mezi aplikacemi. Pro vybudování kompletního řešení to však nestačí. Pro úlohy, které Kafka neřeší, jsou nutné jiné nástroje, jako je Spark. Spark je naopak primárně dávková platforma pro zpracování dat, která čerpá data z Kafkových témat a převádí je do kombinovaných schémat.
#2. Správa paměti
Spark využívá Robust Distributed Datasets (RDD) pro správu paměti. Místo zpracovávání velkých souborů dat je distribuuje přes více uzlů v clusteru. Kafka naopak používá sekvenční přístup podobný HDFS a data ukládá do vyrovnávací paměti.
#3. ETL transformace
Spark i Kafka podporují ETL proces transformace, který kopíruje záznamy z jedné databáze do druhé, obvykle z transakční (OLTP) do analytické (OLAP). Na rozdíl od Sparku, který má zabudovanou funkcionalitu pro ETL, se však Kafka spoléhá na podporu Streams API.
#4. Stálost dat

Využití RRD ve Sparku umožňuje ukládání dat na více místech pro pozdější použití, zatímco v Kafka musíte definovat objekty datové sady v konfiguraci, abyste data zachovali.
#5. Obtížnost
Spark je komplexní řešení a je snadnější na učení díky podpoře různých programovacích jazyků na vysoké úrovni. Kafka je závislá na mnoha různých API a modulech třetích stran, což může ztížit její používání.
#6. Zotavení
Spark i Kafka poskytují mechanismy obnovy. Spark využívá RRD, což mu umožňuje data průběžně ukládat, a v případě selhání clusteru je lze obnovit.

Kafka průběžně replikuje data uvnitř clusteru a mezi brokery, což umožňuje přesun k jinému brokeru v případě selhání.
Podobnosti mezi Sparkem a Kafkou
| Apache Spark | Apache Kafka |
| Open Source | Open Source |
| Vytváří aplikace pro streamování dat | Vytváří aplikace pro streamování dat |
| Podporuje stavové zpracování | Podporuje stavové zpracování |
| Podporuje SQL | Podporuje SQL |
Závěrem
Kafka a Spark jsou open-source nástroje napsané v Scala a Java, které vám umožňují vytvářet aplikace pro streamování dat v reálném čase. Mají několik společných rysů, včetně podpory stavového zpracování, SQL a ETL. Kafka a Spark lze využít i jako doplňkové nástroje pro řešení komplexity přenosu dat mezi aplikacemi.
