Zde je důvod, proč jsou Pandas nejoblíbenější knihovnou pro analýzu dat Pythonu
Pandas je klíčová knihovna pro práci s daty v Pythonu. Její obliba mezi datovými analytiky, vědci a inženýry strojového učení je obrovská.
Společně s knihovnou NumPy tvoří základní sadu nástrojů pro každého, kdo se zabývá daty a umělou inteligencí.
V tomto článku se podíváme na knihovnu Pandas a funkce, které ji činí tak významnou v datovém prostředí.
Co je Pandas?
Pandas představuje softwarovou knihovnu pro analýzu dat v Pythonu. Slouží k efektivnímu zpracování a manipulaci s daty. S knihovnou Pandas můžete data načítat, modifikovat, vizualizovat, analyzovat a ukládat.
Název "Pandas" je odvozen ze slov "Panel Data", což je termín z ekonometrie popisující data získávaná pozorováním více jedinců v čase. Autorem knihovny je Wes Kinney, který ji poprvé vydal v lednu 2008. Od té doby si Pandas získala pozici nejvíce využívané knihovny v dané oblasti.
Základem knihovny Pandas jsou dvě stěžejní datové struktury: Dataframe a Series. Jakmile vytvoříte nebo načtete datovou sadu v Pandas, bude reprezentována jednou z těchto dvou struktur.
Následující část se zaměří na vysvětlení těchto struktur, jejich odlišností a vhodného použití.
Základní datové struktury
Jak již bylo zmíněno, všechna data v Pandas jsou reprezentována pomocí Dataframe nebo Series. Detailní popis obou struktur následuje.
Datový rámec
Následující datový rámec byl vytvořen pomocí kódu uvedeného pod tímto odstavcem.
Dataframe v knihovně Pandas je dvourozměrná datová struktura s řádky a sloupci, podobná tabulce v tabulkovém procesoru nebo databázi.
Skládá se ze sloupců, kde každý sloupec reprezentuje atribut nebo charakteristiku datové sady. Jednotlivé hodnoty v těchto sloupcích jsou uloženy jako objekty Series. Tuto strukturu probereme podrobněji dále v článku.
Sloupce v datovém rámci mohou mít popisné názvy, které je navzájem odlišují. Tyto názvy jsou definovány při vytváření nebo načítání datového rámce, ale lze je kdykoliv změnit.
Hodnoty v jednom sloupci musí být stejného datového typu, avšak sloupce samotné mohou mít různé datové typy. Například sloupec s názvy bude obsahovat textové řetězce, zatímco sloupec s věkem bude obsahovat celá čísla.
Datové rámce disponují indexem sloužícím pro odkazování na řádky. Hodnoty v různých sloupcích se stejným indexem vytváří řádek. Ve výchozím nastavení jsou indexy číselné, ale je možné je upravit tak, aby odpovídaly datové sadě. V našem příkladu (obrázek výše, kód níže) nastavujeme jako index sloupec "měsíce".
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Série
Následující série byla vytvořena pomocí kódu uvedeného pod tímto odstavcem.
Jak již bylo uvedeno, Series slouží k reprezentaci sloupce dat v Pandas. Jedná se tedy o jednorozměrnou datovou strukturu. To je rozdíl oproti datovému rámci, který je dvourozměrný.
I když se Series obvykle používá jako sloupec v datovém rámci, může také reprezentovat samostatnou datovou sadu, pokud obsahuje pouze jeden atribut zaznamenaný v jednom sloupci. Jinými slovy, datová sada je jednoduchý seznam hodnot.
Protože Series představuje pouze jeden sloupec, nemusí mít název. Hodnoty v Series jsou však indexovány. Stejně jako u datového rámce, i u Series lze index upravit od výchozího číselného nastavení.
V příkladu (obrázek výše, kód níže) byl index nastaven na různé měsíce pomocí metody set_axis objektu Pandas Series.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Vlastnosti knihovny Pandas
Nyní, když máme představu o tom, co je knihovna Pandas a jaké datové struktury používá, můžeme se podívat na vlastnosti, které z ní činí tak účinný nástroj pro analýzu dat, a které ji proslavily v oblasti datové vědy a strojového učení.
#1. Manipulace s daty
Objekty Dataframe a Series jsou modifikovatelné. Umožňují přidávání a odebírání sloupců podle potřeby. Dále můžete přidávat řádky a spojovat datové sady.
Můžete provádět numerické výpočty, jako je normalizace dat, logická porovnávání po prvcích. Pandas také umožňuje seskupovat data a používat agregační funkce, jako je průměr, maximum a minimum. Práce s daty v Pandas je tak velmi efektivní.
#2. Čištění dat
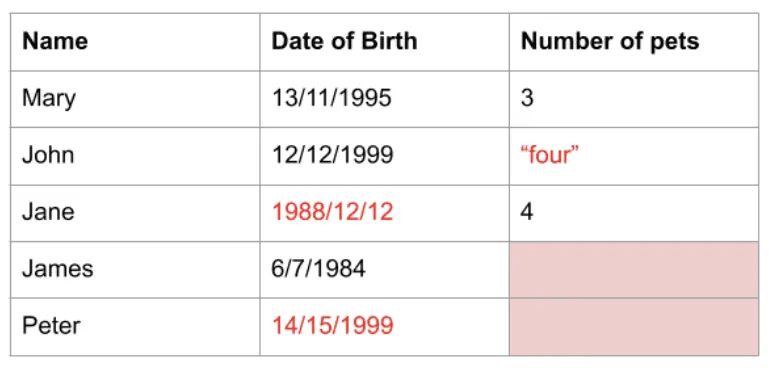
Data z reálného světa obsahují často hodnoty, které komplikují analýzu nebo použití v modelech strojového učení. Může jít o nesprávné datové typy, špatný formát nebo chybějící hodnoty. Tato data je nutné před použitím předzpracovat. Tento proces se nazývá čištění dat.
Pandas má funkce, které pomohou s čištěním dat. Umožňuje například odstranit duplicitní řádky, vypustit sloupce nebo řádky s chybějícími daty, nebo nahradit hodnoty výchozími hodnotami, nebo průměrem daného sloupce. K dispozici je mnoho dalších funkcí a knihoven, které spolupracují s Pandas a umožňují provádět složitější čištění dat.
#3. Vizualizace dat
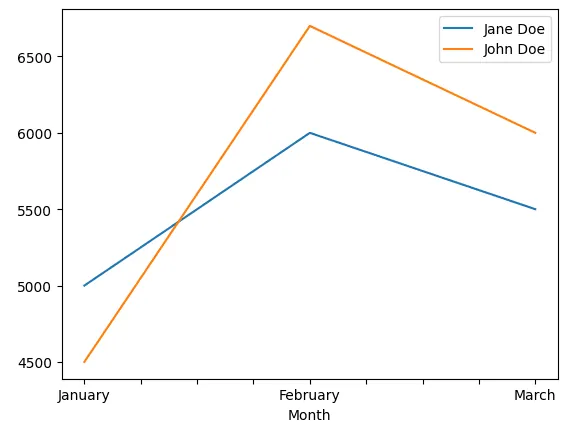 Tento graf byl vygenerován pomocí kódu pod tímto odstavcem.
Tento graf byl vygenerován pomocí kódu pod tímto odstavcem.
Přestože Pandas není knihovnou určenou pro vizualizaci dat jako například Matplotlib, nabízí funkce pro vytváření základních grafů. Ačkoli jsou základní, ve většině případů jsou dostatečné.
S Pandas lze jednoduše vytvářet sloupcové grafy, histogramy, matice rozptylu a další grafy. V kombinaci s možností manipulace s daty v Pythonu můžete vytvářet i složitější vizualizace, které pomohou lépe pochopit data.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Analýza časových řad
Pandas také podporuje práci s daty s časovým razítkem. Když Pandas identifikuje sloupec jako sloupec s hodnotami datetime, můžete na něm provádět různé operace užitečné při práci s časovými řadami.
Můžete například seskupovat pozorování podle časového období a aplikovat agregační funkce, jako je součet nebo průměr, nebo získávat nejstarší a nejnovější pozorování. S časovými řadami v Pandas lze samozřejmě dělat mnohem více.
#5. Vstup/výstup v Pandas
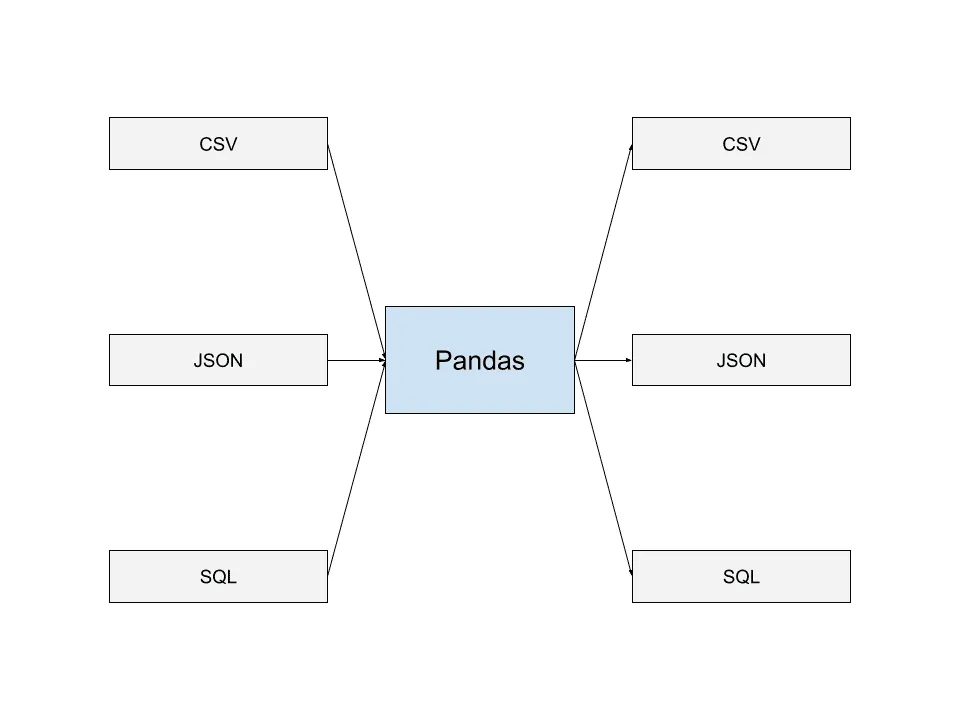
Pandas umí načítat data z nejběžnějších formátů, jako jsou JSON, SQL výpisy a CSV. Data lze také zapisovat do souborů v těchto formátech.
Tato schopnost číst a zapisovat do různých datových formátů umožňuje bezproblémovou spolupráci Pandas s dalšími aplikacemi a vytváření datových kanálů, které se dobře integrují. To je jeden z důvodů, proč je knihovna Pandas hojně využívána.
#6. Integrace s dalšími knihovnami
Pandas má také rozsáhlý ekosystém nástrojů a knihoven, které doplňují jeho funkčnost. Díky tomu je knihovna ještě výkonnější a užitečnější.
Nástroje z ekosystému Pandas rozšiřují jeho možnosti v oblastech, jako je čištění dat, vizualizace, strojové učení, vstup/výstup a paralelní zpracování. Pandas udržuje registr těchto nástrojů ve své dokumentaci.
Úvahy o výkonu a efektivitě v Pandas
Ačkoliv Pandas ve většině operací exceluje, může být i pomalá. Naštěstí lze kód optimalizovat a zrychlit. K tomu je nutné pochopit, jak Pandas funguje.
Pandas je postavena na knihovně NumPy, která slouží pro numerické a vědecké výpočty v Pythonu. Proto stejně jako NumPy funguje Pandas efektivněji, když jsou operace vektorizované, namísto zpracovávání jednotlivých buněk nebo řádků pomocí cyklů.
Vektorizace je forma paralelizace, kde je stejná operace aplikována na více datových bodů najednou. Toto se nazývá SIMD (Single Instruction, Multiple Data). Využití vektorizovaných operací dramaticky zvyšuje rychlost a výkon Pandas.
Datové struktury DataFrame a Series jsou díky využití polí NumPy rychlejší než slovníky a seznamy.
Základní implementace Pandas běží pouze na jednom jádru CPU. Dalším způsobem, jak zrychlit kód, je použití knihoven, které umožní Pandas využít všechna dostupná jádra CPU. Patří sem Dask, Vaex, Modin a IPython.
Komunita a zdroje
Pandas je populární knihovna nejrozšířenějšího programovacího jazyka, a proto má velkou komunitu uživatelů a přispěvatelů. Proto je k dispozici mnoho zdrojů pro studium a výuku. Patří sem oficiální dokumentace Pandas, ale také nespočet kurzů, tutoriálů a knih.
Online komunity lze nalézt na platformách jako Reddit v subredditech r/Python a r/Data Science, kde můžete klást otázky a získávat odpovědi. Protože se jedná o open-source knihovnu, můžete hlásit problémy na GitHubu a dokonce přispívat kódem.
Závěrečná slova
Pandas je velmi užitečná a výkonná datová knihovna. V tomto článku jsme prozkoumali funkce, které z ní dělají oblíbený nástroj pro datové vědce a programátory.
Podívejte se také na článek, jak vytvořit Pandas DataFrame.
