Analyzujte svá data pomocí přirozeného jazyka
Chcete zkoumat svá data pomocí přirozeného jazyka? Objevte, jak na to s pomocí knihovny PandasAI pro Python.
V dnešní době, kdy data hrají klíčovou roli, je jejich analýza a pochopení naprosto zásadní. Tradiční metody analýzy dat mohou být ovšem náročné. Zde přichází ke slovu PandasAI, která zjednodušuje tento proces tím, že vám umožňuje komunikovat s daty pomocí přirozeného jazyka.
PandasAI funguje tak, že vaše dotazy překládá do kódu pro analýzu dat. Využívá populární knihovnu Pandas pro Python. PandasAI je pythonovská knihovna, která rozšiřuje možnosti Pandas, oblíbeného nástroje pro práci s daty, o funkce generativní umělé inteligence. Jejím cílem je doplňovat, nikoli nahrazovat Pandas.
PandasAI přináší do Pandas (a dalších knihoven pro analýzu dat) konverzační prvek, který vám umožňuje komunikovat s vašimi daty prostřednictvím dotazů v běžném jazyce.
V tomto návodu vás provedeme nastavením PandasAI, ukážeme vám, jak ji používat s reálnými daty, jak vytvářet grafy, a prozkoumáme její silné a slabé stránky.
Po dokončení tohoto návodu budete schopni provádět analýzu dat mnohem snáz a intuitivněji díky přirozenému jazyku.
Pojďme se tedy společně ponořit do fascinujícího světa analýzy dat pomocí přirozeného jazyka s PandasAI!
Nastavení vývojového prostředí
Pro začátek s PandasAI je potřeba nainstalovat samotnou knihovnu.
V tomto projektu používám Jupyter Notebook, ale můžete také použít Google Collab nebo VS Code podle svých preferencí.
Pokud plánujete využívat rozsáhlé jazykové modely (LLM) od Open AI, je důležité nainstalovat i Open AI Python SDK.
# Instalace Pandas AI !pip install pandas-ai # Pandas AI využívá jazykové modely OpenAI, je třeba nainstalovat OpenAI Python SDK !pip install openai
Nyní importujeme všechny potřebné knihovny:
# Import nezbytných knihoven import pandas as pd import numpy as np # Import PandasAI a jejích komponent from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Klíčovým prvkem analýzy dat s PandasAI je API klíč. Tento nástroj podporuje různé modely LLM a LangChain, které se používají pro generování kódu z dotazů v přirozeném jazyce. Díky tomu je analýza dat dostupnější a uživatelsky přívětivější.
PandasAI je univerzální a funguje s různými typy modelů, včetně Hugging Face, Azure OpenAI, Google PALM a Google VertexAI. Každý z těchto modelů přináší své výhody a rozšiřuje možnosti PandasAI.
Pro použití těchto modelů budete potřebovat příslušné API klíče. Tyto klíče ověřují vaše požadavky a umožňují vám využívat pokročilé jazykové modely při analýze dat. Ujistěte se, že máte API klíče při ruce, než začnete s konfigurací PandasAI.
API klíč můžete načíst a uložit jako proměnnou prostředí.
V dalším kroku se podíváme na to, jak používat PandasAI s různými typy rozsáhlých jazykových modelů (LLM) od OpenAI a Hugging Face Hub.
Použití rozsáhlých jazykových modelů
Model LLM můžete vybrat buď vytvořením jeho instance a jejím předáním konstruktoru SmartDataFrame nebo SmartDatalake, anebo jej můžete zadat v souboru pandasai.json.
Pokud model očekává jeden nebo více parametrů, můžete je předat konstruktoru nebo je zadat v souboru pandasai.json pod klíčem llm_options, takto:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "VÁŠ_API_TOKEN_ZDE"
}
}
Jak používat modely OpenAI?
Pro používání modelů OpenAI potřebujete API klíč OpenAI. Můžete ho získat zde.
Jakmile máte API klíč, můžete jej použít k vytvoření instance objektu OpenAI:
# Všechny potřebné knihovny jsme importovali v předchozím kroku
llm = OpenAI(api_token="můj-api-klíč")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Nezapomeňte nahradit "můj-api-klíč" vaším skutečným API klíčem.
Alternativně můžete nastavit proměnnou prostředí OPENAI_API_KEY a vytvořit instanci objektu OpenAI bez předávání API klíče:
# Nastavte proměnnou prostředí OPENAI_API_KEY
llm = OpenAI() # není třeba předávat API klíč, bude načten z proměnné prostředí
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Pokud používáte explicitní proxy, můžete ji zadat pomocí parametru openai_proxy při vytváření instance objektu OpenAI nebo nastavením proměnné prostředí OPENAI_PROXY.
Důležitá poznámka: Při používání knihovny PandasAI s API klíčem pro analýzu dat je důležité sledovat spotřebu tokenů pro správu nákladů.
Jak na to? Jednoduše spusťte následující kód pro počítání tokenů, abyste získali jasnou představu o jejich spotřebě a odpovídajících poplatcích. Takto můžete efektivně spravovat své zdroje a předejít překvapením ve vyúčtování.
Počet tokenů použitých dotazem můžete spočítat takto:
"""Příklad použití PandasAI s Pandas DataFrame"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False by mělo snížit spotřebu a náklady
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Spočítej sumu HDP severoamerických zemí")
print(response)
print(cb)
Získáte podobné výsledky:
# Suma HDP severoamerických zemí je 19 294 482 071 552. # Použité tokeny: 375 # Tokeny dotazu: 210 # Tokeny dokončení: 165 # Celkové náklady (USD): $0.000750
Pokud máte omezený kredit, nezapomeňte si evidovat celkové náklady!
Jak používat modely Hugging Face?
Pro používání modelů HuggingFace potřebujete API klíč HuggingFace. Účet si můžete vytvořit zde a API klíč získat zde.
Jakmile máte API klíč, můžete ho použít k vytvoření instance jednoho z modelů HuggingFace.
PandasAI momentálně podporuje tyto modely HuggingFace:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="můj-huggingface-api-klíč")
# nebo
llm = Falcon(api_token="můj-huggingface-api-klíč")
df = SmartDataframe("data.csv", config={"llm": llm})
Alternativně můžete nastavit proměnnou prostředí HUGGINGFACE_API_KEY a vytvořit instanci objektu HuggingFace bez předávání API klíče:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # není třeba předávat API klíč, bude načten z proměnné prostředí
# nebo
llm = Falcon() # není třeba předávat API klíč, bude načten z proměnné prostředí
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder a Falcon jsou oba LLM modely dostupné na Hugging Face.
Úspěšně jsme nastavili vývojové prostředí a prozkoumali, jak používat modely OpenAI a Hugging Face LLM. Nyní se můžeme posunout dál s naší analýzou dat.
Budeme používat dataset Big Mart Sales, který obsahuje informace o prodejích různých produktů v různých prodejnách Big Mart. Soubor dat má 12 sloupců a 8524 řádků. Odkaz na něj najdete na konci článku.
Analýza dat s PandasAI
Nyní, když jsme úspěšně nainstalovali a importovali všechny potřebné knihovny, přejdeme k načtení naší datové sady.
Načtení datové sady
Můžete si vybrat LLM vytvořením instance a jejím předáním do SmartDataFrame. Odkaz na datovou sadu naleznete na konci článku.
# Načtení datové sady z disku path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Použití LLM modelu OpenAI
Po načtení dat budeme pro PandasAI používat LLM model OpenAI.
llm = OpenAI(api_token="API_Klíč") pandas_ai = PandasAI(llm, conversational=False)
Vše je připraveno! Nyní zkusme použít dotazy.
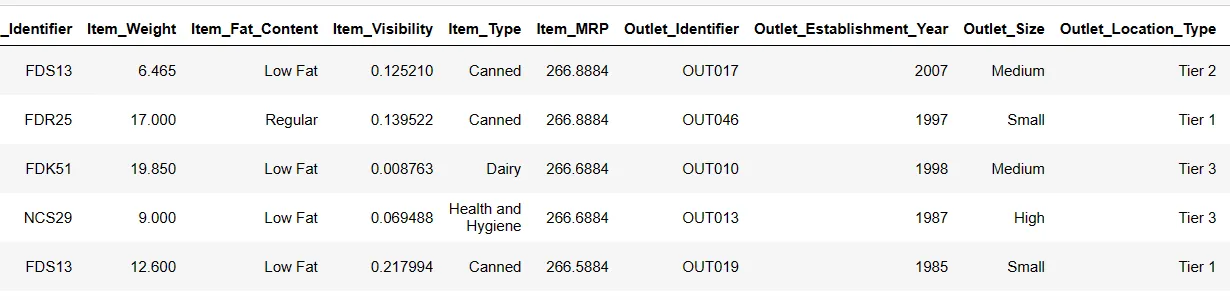
Zobrazení prvních 6 řádků datové sady
Zkusíme zobrazit prvních 6 řádků pomocí instrukce:
Result = pandas_ai(df, "Zobraz prvních 6 řádků dat v tabulce") Result
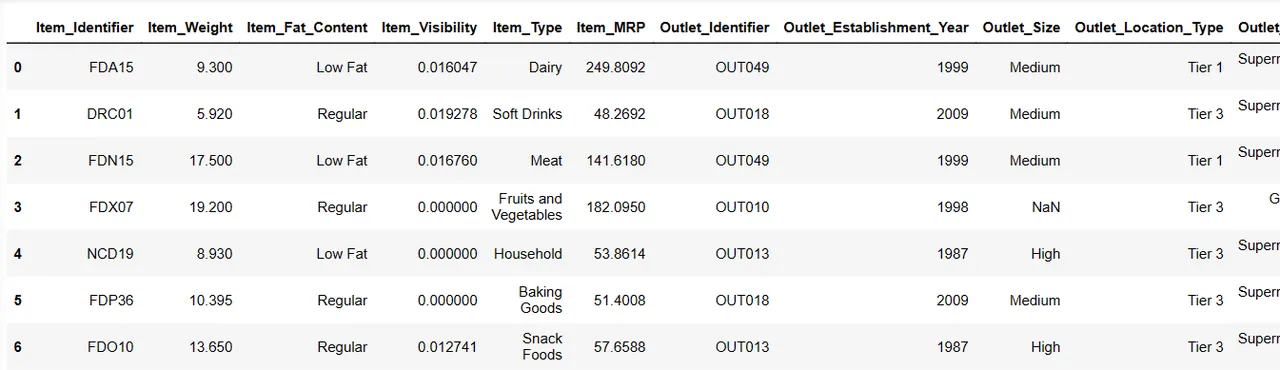 Prvních 6 řádků datové sady
Prvních 6 řádků datové sady
Opravdu rychlé! Pojďme se podívat na naši datovou sadu.
Generování popisné statistiky DataFrame
# Zobrazení popisné statistiky Result = pandas_ai(df, "Zobraz popis dat v tabulce") Result
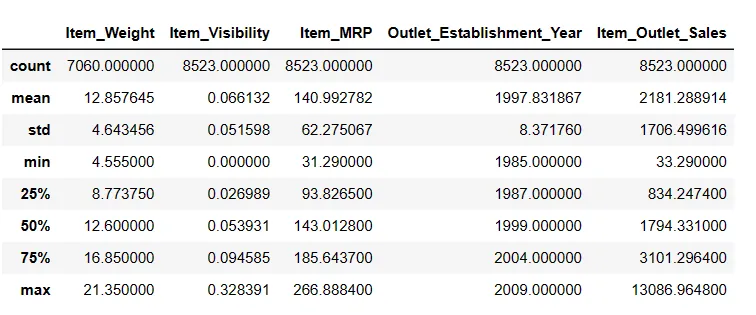 Popisná statistika
Popisná statistika
Sloupec Item_Weight má 7060 hodnot; pravděpodobně tam chybí nějaké hodnoty.
Nalezení chybějících hodnot
Existují dva způsoby, jak najít chybějící hodnoty pomocí PandasAI.
# Nalezení chybějících hodnot Result = pandas_ai(df, "Zobraz chybějící hodnoty v tabulce") Result
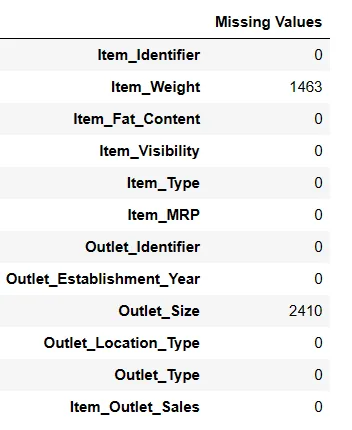 Nalezení chybějících hodnot
Nalezení chybějících hodnot
# Zkratka pro čištění dat
df = SmartDataframe('data.csv')
df.clean_data()
Tato zkratka provede čištění dat v datovém rámci.
Nyní doplníme chybějící hodnoty.
Doplnění chybějících hodnot
# Doplnění chybějících hodnot result = pandas_ai(df, "Doplň Item Weight mediánem a chybějící hodnoty Item outlet size modem a zobraz chybějící hodnoty v tabulce") result
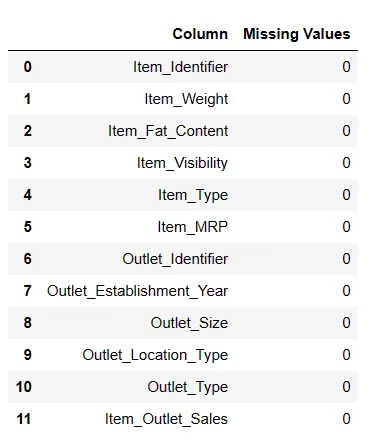 Doplněné chybějící hodnoty
Doplněné chybějící hodnoty
Je to užitečná metoda pro doplnění chybějících hodnot, ale při jejím použití jsem narazil na problémy.
# Zkratka pro doplnění chybějících hodnot
df = SmartDataframe('data.csv')
df.impute_missing_values()
Tato zkratka doplní chybějící hodnoty v datovém rámci.
Smazání chybějících hodnot
Pokud chcete smazat všechny chybějící hodnoty z vašeho DataFrame, můžete použít tuto metodu.
result = pandas_ai(df, "Smaž řádky s chybějícími hodnotami s inplace=True") result
Analýza dat je klíčová pro identifikaci trendů, krátkodobých i dlouhodobých, které mohou být neocenitelné pro podniky, vlády, výzkumníky i jednotlivce.
Zkusme zjistit celkový trend prodeje v průběhu let od založení prodejen.
Zjištění trendu prodeje
# Zjištění trendu prodeje result = pandas_ai(df, "Jaký je celkový trend prodeje v průběhu let od založení prodejen?") result
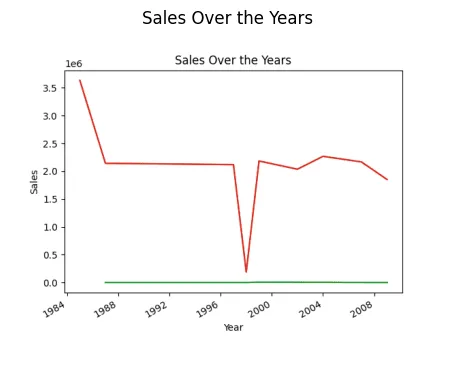 Prodej v průběhu let (liniový graf)
Prodej v průběhu let (liniový graf)
Počáteční proces tvorby grafu byl trochu pomalý, ale po restartu jádra to běželo rychleji.
# Zkratka pro kreslení liniových grafů
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Tato zkratka nakreslí liniový graf datového rámce.
Možná se ptáte, proč je vidět pokles trendu. Je to tím, že nemáme data z let 1989 až 1994.
Nalezení roku s nejvyšším prodejem
Nyní zjistíme, který rok měl nejvyšší prodeje.
# Nalezení roku s nejvyšším prodejem result = pandas_ai(df, "Vyjmenuj roky s nejvyšším prodejem") result
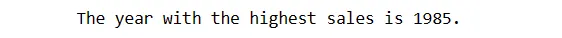
Takže rok s nejvyšším prodejem je 1985.
Chci však zjistit, jaký typ položky generuje nejvyšší průměrné prodeje a jaký typ generuje nejnižší průměrné prodeje.
Nejvyšší a nejnižší průměrné tržby
# Zjištění nejvyšších a nejnižších průměrných tržeb result = pandas_ai(df, "Který typ položky generuje nejvyšší průměrné prodeje a který nejnižší?") result

Škroby mají nejvyšší průměrné tržby a Ostatní mají nejnižší průměrné tržby. Pokud nechcete, aby ostatní měli nejnižší tržby, můžete dotaz upravit podle potřeby.
Skvělé! Nyní chci zjistit rozložení prodeje v různých prodejnách.
Rozložení prodeje v různých prodejnách
Existují čtyři typy prodejen: Supermarket Typ 1/2/3 a Potraviny.
# Rozložení prodeje v různých typech prodejen od založení response = pandas_ai(df, "Vizualizuj rozložení prodeje v různých typech prodejen od založení pomocí sloupcového grafu, velikost grafu=(13,10)") response
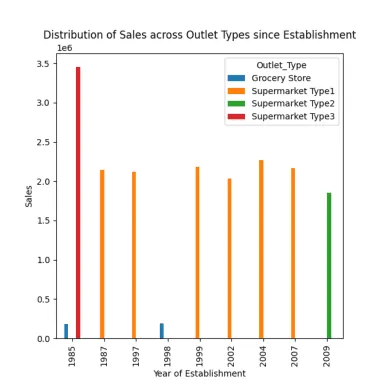 Rozložení prodeje do různých prodejen
Rozložení prodeje do různých prodejen
Jak bylo vidět v předchozích dotazech, vrchol prodeje nastal v roce 1985 a tento graf ukazuje nejvyšší prodeje v roce 1985 v supermarketech typu 3.
# Zkratka pro kreslení sloupcového grafu
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Tato zkratka vykreslí sloupcový graf datového rámce.
# Zkratka pro kreslení histogramu
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Tato zkratka vykreslí histogram datového rámce.
Nyní zjistíme, jaké jsou průměrné prodeje položek s obsahem tuku „nízkotučné“ a „běžné“.
Zjištění průměrných prodejů položek s různým obsahem tuku
# Zjištění indexu řádku podle hodnoty sloupce result = pandas_ai(df, "Jaký je průměrný prodej položek s obsahem tuku 'Low Fat' a 'Regular'?") result
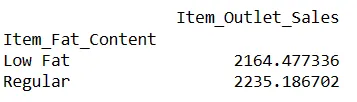
Dotazy jako tento vám umožní porovnat dva nebo více produktů.
Průměrný prodej pro každý typ položky
Chci porovnat všechny produkty s jejich průměrným prodejem.
# Průměrný prodej pro každý typ položky result = pandas_ai(df, "Jaké jsou průměrné prodeje pro každý typ položky za posledních 5 let?, použijte koláčový graf, velikost=(6,6)") result
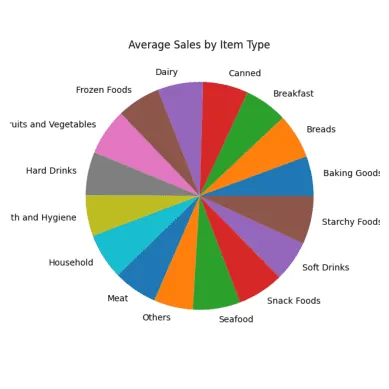 Koláčový graf průměrného prodeje
Koláčový graf průměrného prodeje
Všechny části koláčového grafu vypadají podobně, protože mají téměř stejné hodnoty prodeje.
# Zkratka pro kreslení koláčového grafu
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Tato zkratka nakreslí koláčový graf datového rámce.
Top 5 nejprodávanějších typů položek
I když jsme již porovnali všechny produkty na základě průměrného prodeje, nyní bych chtěl určit 5 nejlepších položek s nejvyšším prodejem.
# Zjištění 5 nejprodávanějších položek result = pandas_ai(df, "Jakých je 5 nejprodávanějších typů položek podle průměrných prodejů? Zobraz v tabulce") result
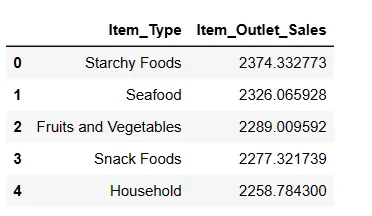
Nejprodávanějším artiklem na základě průměrných tržeb jsou, jak se dalo očekávat, škroby.
Top 5 nejméně prodávaných typů položek
result = pandas_ai(df, "Jakých je 5 nejméně prodávaných typů položek podle průměrných prodejů?") result
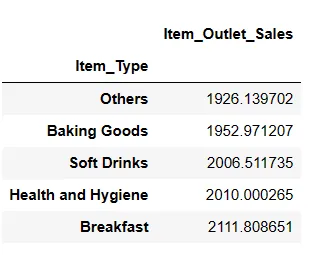
Možná budete překvapeni, že vidíte nealkoholické nápoje v kategorii nejméně prodávaných. Je ovšem potřeba dodat, že tato data sahají jen do roku 2008 a trend nealkoholických nápojů vzrostl až o pár let později.
Prodej kategorií produktů
Zde jsem použil slovo "kategorie produktu" namísto "typ položky" a PandasAI stále vytvořil grafy, které dokazují, že rozumí podobným slovům.
result = pandas_ai(df, "Vytvořte skládaný sloupcový graf prodeje různých kategorií produktů za poslední fiskální rok") result
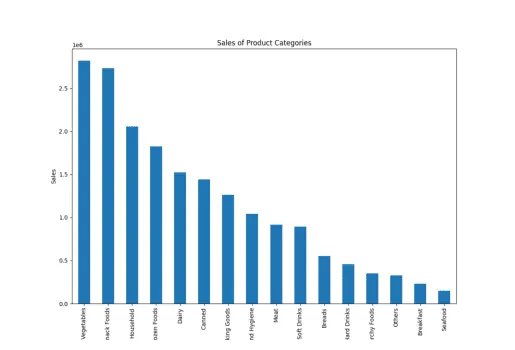 Prodej typů zboží
Prodej typů zboží
Ostatní zkratky najdete zde.
Můžete si všimnout, že když napíšeme dotaz a dáme instrukce PandasAI, dostáváme výsledky založené čistě na tomto konkrétním dotazu. Nástroj neanalyzuje vaše předchozí dotazy, aby nabízel přesnější odpovědi.
S pomocí chatovacího agenta však můžete dosáhnout i této funkce.
Chatovací agent
S chatovacím agentem se můžete zapojit do dynamických konverzací, kde si agent během diskuse pamatuje kontext. To vám umožní mít interaktivnější a smysluplnější výměny.
Mezi klíčové funkce, které umožňují tuto interakci, patří Context Retention (uchování kontextu), kdy si agent pamatuje historii konverzace, což umožňuje plynulé, kontextové interakce. Pomocí funkce Clarification Questions (doplňující otázky) můžete požádat o vysvětlení jakéhokoli aspektu konverzace a ujistit se, že plně rozumíte poskytnutým informacím.
Navíc je k dispozici funkce Explain (vysvětlit), která umožňuje získat podrobné vysvětlení toho, jak agent dospěl ke konkrétnímu řešení nebo reakci, a nabízí tak transparentnost a náhled do rozhodovacího procesu agenta.
Neváhejte zahajovat konverzace, vyžádat si vysvětlení a prozkoumat vysvětlení pro zlepšení vašich interakcí s chatovacím agentem!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Jakých je 5 položek s nejvyšším MRP")
result
Na rozdíl od SmartDataframe nebo SmartDatalake bude agent sledovat stav konverzace a bude schopen reagovat na konverzace s více odbočkami.
Pojďme se podívat na výhody a omezení PandasAI.
Výhody PandasAI
Používání PandasAI přináší několik výhod, které z ní dělají cenný nástroj pro analýzu dat, například:
- Dostupnost: PandasAI zjednodušuje analýzu dat a zpřístupňuje ji široké škále uživatelů. Kdokoli, bez ohledu na své technické zázemí, ji může použít k získávání informací z dat a zodpovězení obchodních otázek.
- Dotazy v přirozeném jazyce: Možnost klást otázky přímo a přijímat odpovědi z dat pomocí dotazů v přirozeném jazyce činí průzkum a analýzu dat uživatelsky přívětivější. Tato funkce umožňuje efektivní interakci s daty i netechnickým uživatelům.
- Funkce chatu agenta: Funkce chatu umožňuje uživatelům interaktivně pracovat s daty, zatímco funkce chatu agenta využívá předchozí historii chatu k poskytování kontextových odpovědí. To podporuje dynamický a konverzační přístup k analýze dat.
- Vizualizace dat: PandasAI poskytuje řadu možností vizualizace dat, včetně heatmap, bodových grafů, sloupcových grafů, koláčových grafů, spojnicových grafů a dalších. Tyto vizualizace pomáhají pochopit a prezentovat datové vzory a trendy.
- Zkratky šetřící čas: Dostupnost zkratek a funkcí šetřících čas zefektivňuje proces analýzy dat a pomáhá uživatelům pracovat efektivněji.
- Kompatibilita souborů: PandasAI podporuje různé formáty souborů, včetně CSV, Excel, Google Sheets a dalších. Tato flexibilita umožňuje uživatelům pracovat s daty z různých zdrojů a formátů.
- Vlastní dotazy: Uživatelé mohou vytvářet vlastní dotazy pomocí jednoduchých instrukcí a kódu Pythonu. Tato funkce umožňuje uživatelům přizpůsobit své interakce s daty tak, aby vyhovovaly konkrétním potřebám a dotazům.
- Uložení změn: Možnost uložit změny provedené v datových rámcích zajišťuje, že vaše práce zůstane zachována a můžete se k analýze kdykoli vrátit a sdílet ji.
- Vlastní odpovědi: Možnost vytvářet vlastní odpovědi umožňuje uživatelům definovat konkrétní chování nebo interakce, díky čemuž je nástroj ještě všestrannější.
- Integrace modelu: PandasAI podporuje různé jazykové modely, včetně Hugging Face, Azure, Google Palm, Google VertexAI a LangChain. Tato integrace rozšiřuje možnosti nástroje a umožňuje pokročilé zpracování přirozeného jazyka a pochopení.
- Vestavěná podpora LangChain: Vestavěná podpora pro modely LangChain dále rozšiřuje řadu dostupných modelů a funkcí a zvyšuje hloubku analýzy a náhledů, které lze odvodit z dat.
- Pochopení názvů: PandasAI demonstruje schopnost porozumět korelaci mezi názvy sloupců a skutečnou terminologií. I když například v dotazech použijete výrazy jako "kategorie produktu" namísto "typ položky", nástroj může stále poskytovat relevantní a přesné výsledky. Tato flexibilita při rozpoznávání synonym a jejich mapování do příslušných datových sloupců zvyšuje uživatelské pohodlí a přizpůsobivost nástroje pro dotazy v přirozeném jazyce.
Přestože PandasAI nabízí několik výhod, má také některá omezení a výzvy, které by uživatelé měli brát v úvahu.
Omezení PandasAI
Zde jsou některá omezení, která jsem zaznamenal:
- Požadavek na API klíč: Chcete-li používat PandasAI, je nezbytné mít API klíč. Pokud na svém OpenAI účtu nemáte dostatek kreditu, službu pravděpodobně nebudete moci využívat. Stojí však za zmínku, že OpenAI poskytuje novým uživatelům kredit ve výši 5 USD, což je pro nové uživatele výhodné.
- Doba zpracování: Služba někdy může zaznamenat zpoždění při poskytování výsledků, což lze připsat velkému provozu nebo zatížení serveru. Uživatelé by měli být připraveni na možné čekací doby při zadávání dotazů.
