Jak analyzovat text
Jestliže jste se seznámili s několika programovacími jazyky, pravděpodobně jste se setkali s pojmem analýza textu. Ta slouží ke zjednodušení složitých datových struktur v souboru. Tento článek vás provede procesem analýzy textu s použitím různých technik. Pokud se setkáte s chybou "analýza textu x", najdete zde také rady, jak ji vyřešit.
Jak efektivně analyzovat text
V tomto průvodci se dozvíte o různých metodách analýzy textu, včetně stručného úvodu do tohoto konceptu.
Co vlastně je analýza textu?
Než se pustíme do samotné praxe, je důležité porozumět základním konceptům analýzy textu. Znalost programovacích základů je zde klíčová.
NLP, neboli zpracování přirozeného jazyka
Pro analýzu textu se často využívá zpracování přirozeného jazyka (NLP), což je podoblast umělé inteligence. Python je jedním z jazyků, které se v této oblasti běžně používají.
NLP umožňuje počítačům rozumět a zpracovávat lidskou řeč. Aby bylo možné na text aplikovat metody strojového učení (ML), je nutné nestrukturovaná textová data převést na strukturovaná tabulková data. Python se využívá pro úpravu programového kódu, který toto umožní.
Definice analýzy textu
Analýza textu jednoduše znamená převod dat z jednoho formátu do druhého. Souborový formát musí být transformován, aby byl použitelný v různých aplikacích.
- Zjednodušeně řečeno, jde o rozklad řetězce nebo textu na logické komponenty s cílem změnit formát souboru.
- K provedení tohoto běžného programovacího úkolu se využívají specifická pravidla jazyka Python. Při analýze textu se vstupní text dělí na menší části.
Proč je analýza textu důležitá?
Důvody, proč je potřeba text analyzovat, jsou uvedeny níže. Je důležité je znát, než se pustíte do samotné analýzy.
- Data v počítačích se nevyskytují vždy ve stejném formátu a mohou se lišit v závislosti na použité aplikaci.
- Různé aplikace vyžadují odlišné formáty dat a nekompatibilní formát by mohl vést k chybám.
- Neexistuje univerzální program, který by zpracoval všechny formáty dat.
Metoda 1: Použití třídy DataFrame
Třída DataFrame v Pythonu nabízí všechny potřebné funkce pro analýzu textu. Tato vestavěná knihovna obsahuje kódy pro transformaci dat libovolného formátu.
Stručný úvod do třídy DataFrame
Třída DataFrame je robustní datová struktura, která se používá jako analytický nástroj. Je výkonná a umožňuje analýzu dat s minimálním úsilím.
- Kód se načítá do datového rámce pandas, který se používá pro samotnou analýzu v jazyce Python.
- Třída je součástí balíků, které pandas poskytuje. Tyto balíky jsou populární mezi datovými analytiky v Pythonu.
- Tato třída nabízí abstrakci – interní funkčnost je skryta uživatelům, využívá se i knihovna NumPy, která obsahuje příkazy a funkce pro práci s poli.
- Třídu DataFrame lze využít pro zobrazení dvourozměrného pole s indexy řádků a sloupců. Tyto indexy usnadňují ukládání vícerozměrných dat. Ty je nutné transformovat pro odstranění případné chyby analýzy.
Python pandas pomáhá při provádění databázových operací (styl SQL) s maximální přesností, aby se předešlo chybám při analýze textu. Obsahuje také IO nástroje pro práci se soubory CSV, MS Excel, JSON, HDF5 a dalšími formáty.
Postup analýzy textu pomocí třídy DataFrame
Standardní postup pro analýzu textu s použitím třídy DataFrame je popsán níže:
- Identifikujte datový formát vstupních dat.
- Rozhodněte o formátu výstupních dat (např. CSV).
- Napište kód s primitivním datovým typem (seznam, slovník).
Poznámka: Psaní kódu na prázdný DataFrame může být časově náročné. Pandas umožňuje vytvářet data ve třídě DataFrame přímo z těchto datových typů. Data v primitivním datovém typu tak lze snadno převést na požadovaný formát.
- Analyzujte data pomocí nástroje pandas DataFrame a vytiskněte výsledek.
Varianta I: Standardní formát
Zde je vysvětlena metoda pro zpracování souboru s daty ve formátu CSV.
- Uložte soubor s daty lokálně do počítače (např. data.txt).
- Importujte soubor pomocí knihovny pandas a načtěte data do proměnné (pandas se zde importuje jako pd).
- Import musí zahrnovat kód s detaily o názvu, funkci a formátu vstupního souboru.
Poznámka: Proměnná "res" se zde používá k provedení funkce čtení dat ze souboru data.txt pomocí knihovny pandas importované jako "pd". Formát vstupního textu je určen jako CSV.
- Zavolejte pojmenovaný typ souboru a analyzujte text do výstupního formátu (např. příkaz res zobrazí výsledek analýzy).
Níže je uveden příklad kódu, který demonstruje výše popsaný postup:
import pandas as pd res = pd.read_csv(‘data.txt’) res
V tomto případě, pokud data v souboru data.txt budou [1,2,3], výstup bude 1 2 3.
Varianta II: Metoda řetězce
Pokud text obsahuje pouze řetězce, lze pro oddělení a analýzu textu použít speciální znaky (čárky, mezery). Postup je podobný jako u běžných operací s řetězci. Postupujte podle následujících kroků, abyste předešli chybě analýzy textu:
- Data se extrahují z řetězce a zaznamenají se všechny speciální znaky oddělující text.
V následujícím příkladu jsou speciální znaky v řetězci 'my_string' (',', ':'). Tento proces je třeba provádět pečlivě, aby se předešlo chybě analýzy.
- Text v řetězci se rozdělí na základě hodnot a pozic speciálních znaků.
Řetězec se rozdělí na textová data pomocí příkazu split.
- Hodnoty dat se vytisknou jako analyzovaný text. Příkaz print se použije pro výstup analyzovaných dat.
Níže je uveden ukázkový kód:
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
Výsledný analyzovaný řetězec se zobrazí takto:
Names: [‘Tech’, ‘computer’]
Pro lepší pochopení procesu se používá cyklus for a kód je upraven takto:
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
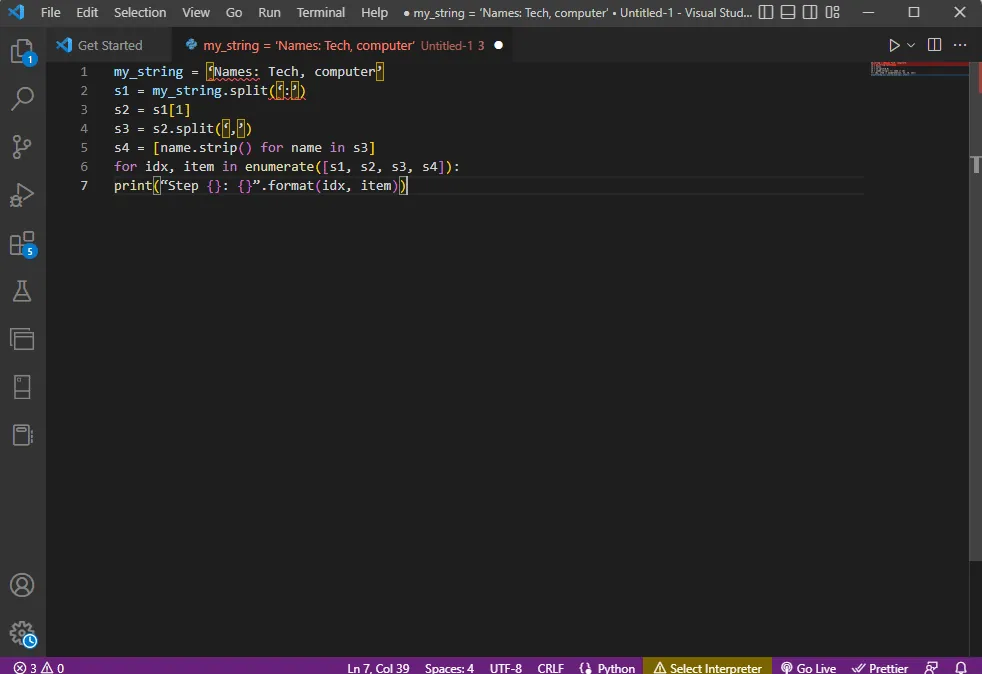
Výsledky analyzovaného textu pro každý krok se zobrazí takto. V kroku 0 je řetězec rozdělen podle speciálního znaku ':' a v dalších krocích se textová data dělí podle dalších znaků.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Varianta III: Analýza komplexního souboru
V mnoha případech data v souboru obsahují různé typy dat. V takových případech může být analýza souboru obtížná.
Funkce analýzy komplexních dat je ta, že se hodnoty dat zobrazují v tabulkové formě.
- Název nebo metadata hodnot se vytisknou v horní části souboru.
- Proměnné a pole jsou zobrazeny v tabulkové formě.
- Hodnoty dat tvoří složený klíč.
Před tím, než se ponoříte do této metody, je nutné se seznámit s některými základními pojmy. Analýza datových hodnot se provádí na základě regulárních výrazů (Regex).
Vzory Regex
Pro eliminaci chyb při analýze textu je nutné zajistit, aby byly vzory regulárních výrazů správné. Kód pro analýzu datových hodnot by měl zahrnovat následující vzory:
-
‘d’ : odpovídá číslici.
-
‘s’ : odpovídá mezeře.
-
‘w’ : odpovídá alfanumerickému znaku.
-
‘+’ nebo ‘*’ : odpovídá jednomu nebo více znakům v řetězci.
-
‘a-z’ : odpovídá malým písmenům.
-
‘A-Z’ nebo ‘a-z’ : odpovídá velkým a malým písmenům.
-
‘0-9’ : odpovídá číselným hodnotám.
Regulární výrazy
Moduly regulárních výrazů jsou klíčovou součástí balíčku pandas v jazyce Python. Nesprávné re může vést k chybám. Regex je malý jazyk vložený do Pythonu pro vyhledávání vzorů. Regulární výrazy jsou řetězce se speciální syntaxí, které umožňují uživateli porovnat vzory v jiných řetězcích.
Regex se vytváří na základě datového typu a požadavku na výraz v řetězci (např. ‘String = (.*)n’). Symboly používané v regulárních výrazech jsou:
-
. : pro načtení libovolného znaku.
-
* : pro nula nebo více dat z předchozího výrazu.
-
(.*) : pro seskupení části regulárního výrazu do závorek.
-
n : pro nový řádek.
-
d : pro krátkou celočíselnou hodnotu (0–9).
-
+ : pro jedno nebo více dat z předchozího výrazu.
-
| : pro logické "nebo".
RegexObjects
RegexObject je návratová hodnota pro funkci kompilace a vrací objekt MatchObject, pokud výraz odpovídá.
1. MatchObject
Logická hodnota MatchObject je vždy True. Příkaz if se používá k identifikaci shod. Pro určení shody se používá skupina, na kterou se odkazuje index.
-
group() : vrací jednu nebo více podskupin shody.
-
group(0) : vrací celý zápas.
-
group(1) : vrací první podskupinu v závorkách.
- Pro odkazování na více skupin se používá rozšíření specifické pro Python, které určuje název skupiny. Například (?P
regulární výraz1) odkazuje na skupinu s názvem skupina1. Je důležité se ujistit, že je skupina správně nasměrována.
2. Metody MatchObject
MatchObject má dvě základní metody. Pokud je nalezen MatchObject, vrátí svoji instanci. V opačném případě vrátí None.
- Metoda match(string) se používá pro shodu na začátku regulárního výrazu.
- Metoda search(string) se používá pro hledání shody v řetězci.
Funkce regulárních výrazů
Funkce regulárních výrazů jsou řádky kódu pro provedení určité operace definované uživatelem.
Poznámka: Pro zápis funkcí se používají "raw strings", aby se předešlo chybám. Provedete to přidáním "r" před vzor ve výrazu.
Běžné funkce používané ve výrazech:
1. re.findall()
Tato funkce vrací všechny vzory v řetězci (pokud shoda existuje). Pokud není shoda nalezena, vrací prázdný seznam. Funkce string = re.findall(‘[aeiou]’, název_souboru) se například používá k nalezení samohlásek v názvu souboru.
2. re.split()
Tato funkce slouží k rozdělení řetězce, pokud se nalezne shoda se zadaným znakem. Pokud shoda neexistuje, vrátí se prázdný řetězec.
3. re.sub()
Tato funkce nahradí odpovídající text obsahem dané proměnné. Pokud není nalezen žádný vzor, vrací se původní řetězec.
4. re.search()
Základní funkce pro hledání vzoru v řetězci a vrácení objektu shody. Pokud vyhledávání selže, nevrací se žádná hodnota.
5. re.compile(vzor)
Tato funkce se používá pro kompilaci vzorů regulárních výrazů do objektu RegexObject.
Další požadavky
Následující požadavky jsou používány pokročilými programátory pro analýzu dat:
- regexper pro vizualizaci regulárních výrazů.
- regex101 pro testování regulárních výrazů.
Postup analýzy textu
Postup analýzy textu v této variantě je popsán níže:
- Důležité je porozumět vstupnímu formátu přečtením obsahu souboru. (funkce open a read() se používají k otevření a čtení obsahu souboru - např. sample.txt).
- Obsah souboru se vytiskne pro ruční analýzu.
- Do kódu se importují potřebné balíčky (regulární výrazy a pandas).
- Regulární výrazy se definují (vzor a funkce).
- Funkce compile() se používá pro kompilaci řetězce.
- Řádkový analyzátor je definován (def_parse_file). Metoda regex search() hledá klíč "rx" a vrací klíč a shodu. Jakýkoli problém v tomto kroku může vést k chybě analýzy textu.
- Následuje definice analyzátoru souborů (def_parse_file). Vytvoří se prázdný seznam pro shromažďování dat (data = []) a shoda se kontroluje na každém řádku.
- Příkaz line.strip().split(‘,’) se používá k extrakci čísel a hodnot. Příkaz row{} vytvoří slovník s daty. data.append(row) slouží pro pochopení a analýzu dat do tabulkového formátu.
Příkaz data = pd.DataFrame(data) se používá pro vytvoření datového rámce pandas z hodnot dict. Můžete použít i další příkazy:
-
data.set_index(['string', 'integer'], inplace=True) pro nastavení indexu tabulky.
-
data = data.groupby(level=data.index.names).first() pro odstranění "nans".
-
data = data.apply(pd.to_numeric, errors='ignore') pro převod hodnot na číselné.
Posledním krokem je otestování analyzátoru a tisk dat pomocí příkazu print(data).
Níže je uveden příklad:
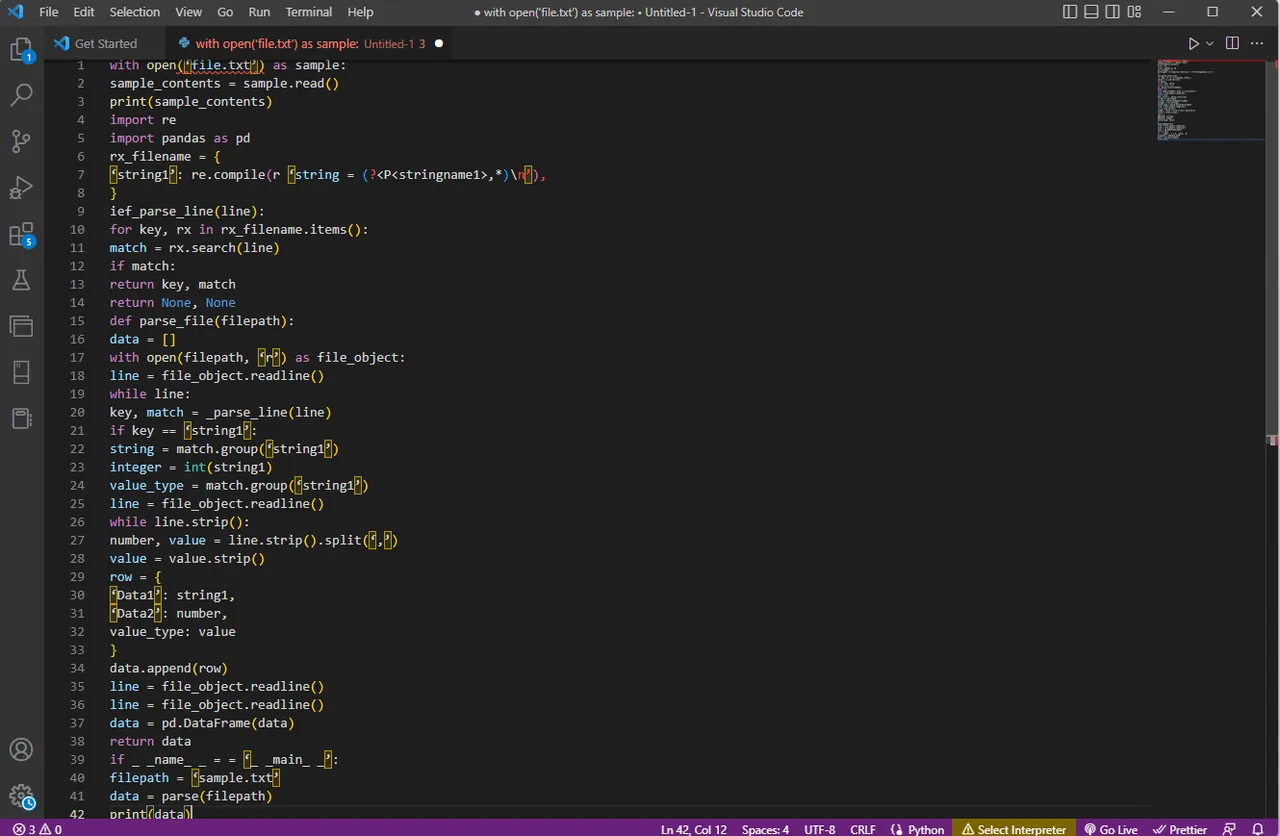
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metoda 2: Tokenizace slov
Proces převodu textu na tokeny (menší části) na základě určitých pravidel se nazývá tokenizace. Je důležité analyzovat příkazy tokenizace slov v kódu. V této metodě se vytváří vlastní pravidla a pomáhá v úlohách předběžného zpracování textu. Můžeme zde vyhledávat a přiřazovat běžná slova, čistit text a připravovat data pro pokročilé techniky textové analýzy (např. analýza sentimentu). Pokud je tokenizace nesprávná, může dojít k chybě.
Knihovna Ntlk
Tato metoda využívá populární knihovnu jazykových nástrojů nltk. Tu si můžete stáhnout pomocí pip. Je také součástí základního balíčku distribuce Anaconda.
Formy tokenizace
Běžnými formami tokenizace jsou tokenizace slov a tokenizace vět. Token na úrovni slova vytiskne jedno slovo pouze jednou, zatímco token na úrovni věty vytiskne slovo v kontextu věty.
Postup analýzy textu
- Importuje se knihovna ntlk.
- Zadá se řetězec a příkazy pro tokenizaci.
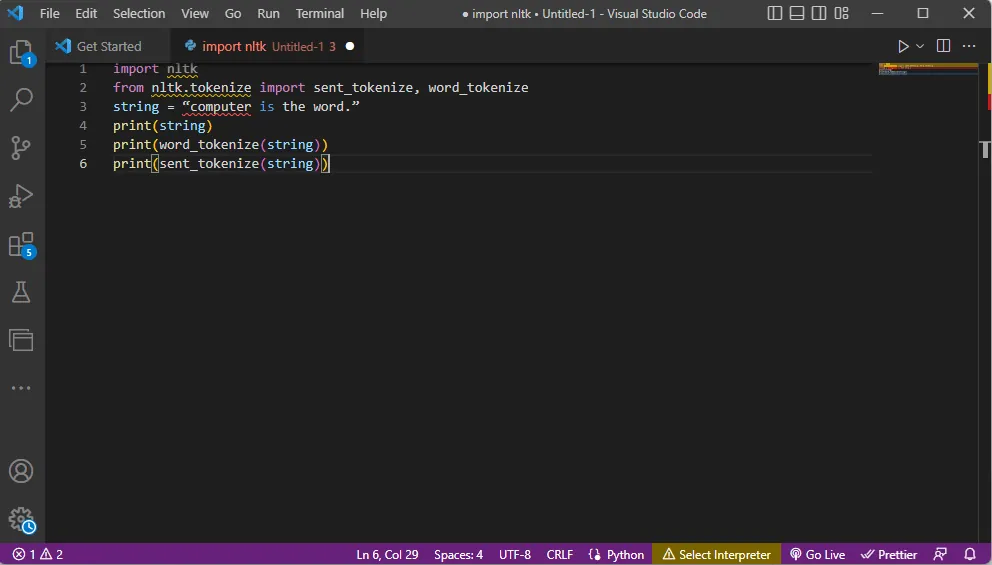
- Pokud vytiskneme řetězec, výstupem bude "počítač je slovo.".
- V případě tokenizace slova (word_tokenize()) se každé slovo tiskne jednotlivě oddělené čárkou ("počítač", "je", "slovo", ".").
- V případě tokenizace věty (sent_tokenize()) se jednotlivé věty vkládají do " " a je povoleno opakování ("počítač je slovo.").
Kód pro demonstraci výše uvedených kroků:
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metoda 3: Třída DocParser
Stejně jako třídu DataFrame, lze třídu DocParser použít pro analýzu textu. Třída umožňuje volání funkce parse s cestou k souboru.
Postup analýzy textu
Pro analýzu textu pomocí třídy DocParser postupujte následovně:
- Funkce get_format(název_souboru) se používá pro extrahování přípony souboru.
- Logická struktura je vytvořena pomocí příkazů if-elif-else.
- Pokud je přípona souboru platná, funkce get_parser analyzuje data a vrací objekt string.
Poznámka: Je důležité, aby byla tato funkce správně implementována.
- Analýza se provádí na základě přípony souboru. Pro generování objektu string se používají implementace třídy (parse_txt, parse_docx).
- Analýza se provádí i pro další přípony souborů (parse_pdf, parse_html, parse_pptx).
- Hodnoty a rozhraní dat se importují do aplikací pomocí příkazů importu a vytvoří se instance DocParser. Analýzu souborů lze provést pomocí skriptu parse_file.py.
Metoda 4: Nástroj pro analýzu textu
Textový nástroj Parse extrahuje data z proměnných a mapuje je na jiné proměnné. Je nezávislý na jiných nástrojích. Nástroj BPA Platform se používá ke zpracování proměnných. Nástroj pro analýzu textu online naleznete zde.
Metoda 5: TextFieldParser (Visual Basic)
TextFieldParser se používá pro analýzu velkých strukturovaných souborů. V této metodě lze použít šířku a sloupec textu (např. soubory protokolu). Metoda je podobná iteraci kódu přes textový soubor, extrahují se textová pole. Provádí se tokenizace oddělených řetězců pomocí oddělovače (např. čárka, tabulátor).
Funkce pro analýzu textu
Pro analýzu textu v této metodě se používají následující funkce:
- SetDelimiters definuje oddělovač (testReader.SetDelimiters(vbTab) nastaví tabulátor jako oddělovač).
- SetFieldWidths(integer) nastaví šířku pole na pevnou šířku.
- testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth otestuje typ pole textu.
Metody pro nalezení MatchObject
Existují dvě základní metody pro nalezení MatchObject:
- První metoda definuje formát a prochází soubor pomocí metody ReadFields. Tato metoda zpracuje každý řádek kódu.
- Metoda PeekChars zkontroluje každé pole před jeho čtením.
V obou případech, pokud pole neodpovídá formátu, vrátí se výjimka MalformedLineException.
Tip pro profesionály: MS Excel
MS Excel lze využít k analýze textu, např. při vytváření souborů oddělených tabulátory. Může pomoci při kontrole s vaším analyzovaným výsledkem.
1. Vyberte data a stiskněte Ctrl + C pro kopírování.
2. Spusťte aplikaci Excel.
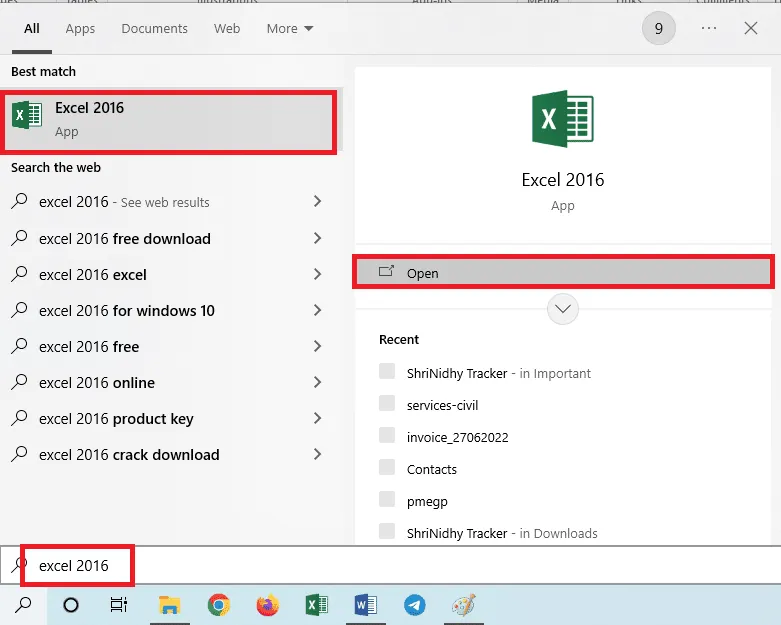
3. Klikněte na buňku A1 a stiskněte Ctrl + V pro vložení.
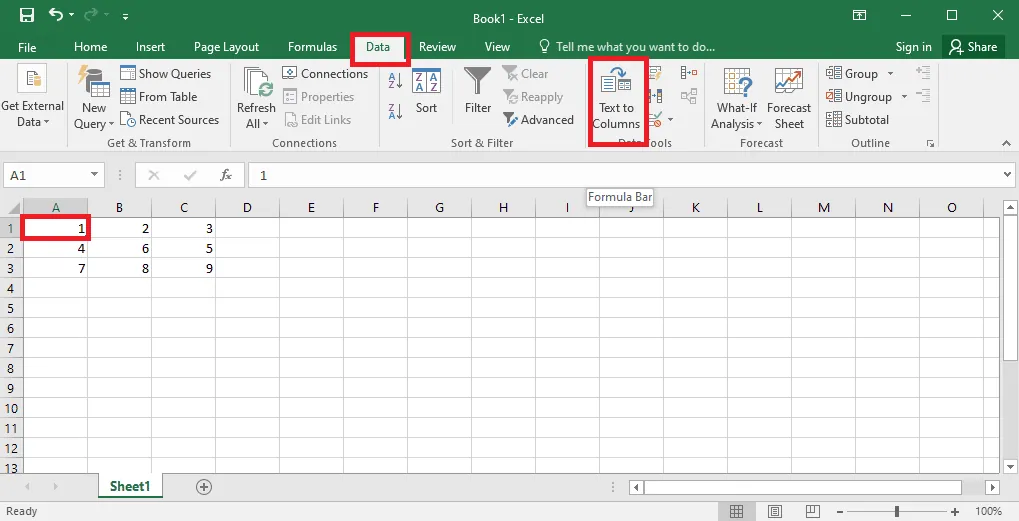
4. Vyberte buňku A1, přejděte na kartu Data a klikněte na možnost Text do sloupců.
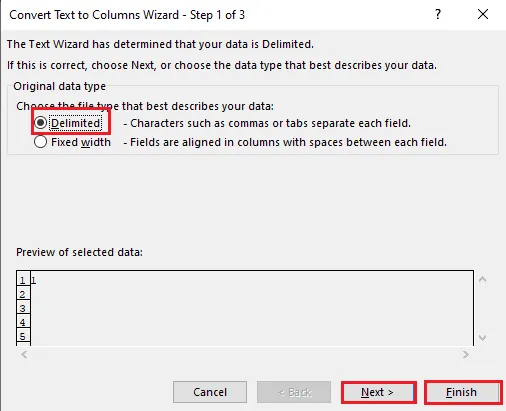
5A. Pokud se jako oddělovač používá čárka nebo tabulátor, vyberte možnost Oddělovač a klikněte na Další a Dokončit.
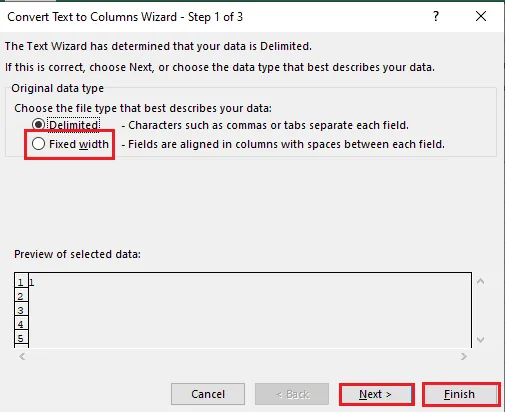
5B. Vyberte možnost Pevná šířka, přiřaďte hodnotu oddělovači a klikněte na Další a Dokončit.
Jak opravit chybu analýzy
Chyba analýzy textu "x" se může objevit na zařízeních Android (např. Chyba při analýze balíčku). Obvykle se objevuje, pokud se aplikaci nepodaří nainstalovat z Obchodu Google Play nebo je spuštěna aplikace třetí strany.
Chyba textu "x" se může objevit i v případech, kdy je seznam znakových vektorů zacyklený. Chybová zpráva je: "Error in parse(text = x, keep.source = FALSE):
V dalším článku si můžete přečíst o tom, jak opravit tuto chybu v systému Android.
Kromě řešení v uvedeném průvodci můžete vyzkoušet i následující opravy:
- Opětovné stažení souboru .apk.
- Obnovení změn v souboru Androidmanifest.xml (pokud máte expertní znalosti programování).
***
Tento článek poskytuje návod, jak analyzovat text a jak opravit chybu analýzy. Dejte nám vědět, která z uvedených metod vám pomohla. Sdílejte své návrhy a dotazy v sekci komentářů.
