Jak je efektivně používat?
Jestliže s Linuxem pracujete delší dobu, s nástrojem grep – Global Regular Expression Print, jste se již nepochybně setkali. Jedná se o textový procesor, který umožňuje prohledávání souborů a adresářů. V rukou zkušeného uživatele Linuxu je tento nástroj velice mocný. Nicméně, pokud ho používáte bez regulárních výrazů, jeho potenciál je do jisté míry omezen.
Co jsou vlastně Regex?
Regex, neboli regulární výrazy, jsou pokročilé vzory, které slouží k filtrování výstupu a výraznému zlepšení vyhledávacích schopností nástroje grep. S praxí si osvojíte jejich efektivní používání a zjistíte, že se dají aplikovat i s dalšími linuxovými příkazy.
V tomto tutoriálu si ukážeme, jak efektivně využívat kombinaci příkazů grep a Regex.
Požadavky
Pro efektivní použití grep s regulárními výrazy je nutná alespoň základní znalost operačního systému Linux. Pokud jste v Linuxu nováčci, doporučujeme vám projít si naše úvodní příručky.
Dále budete potřebovat počítač s nainstalovaným Linuxem. Je možné použít jakoukoli linuxovou distribuci. Majitelé počítačů s Windows mohou použít Linux prostřednictvím WSL2. Podrobný návod naleznete zde.
Pro spouštění příkazů z našeho tutoriálu je nutný přístup k příkazovému řádku, neboli terminálu.
K testování příkladů budete potřebovat i textové soubory. Pro tyto účely jsem použil nástroj ChatGPT k vytvoření textového souboru s tematikou technologií. Zadání pro ChatGPT bylo následující:
„Vygeneruj 400 slov o technologiích. Text by měl pokrývat různé oblasti techniky a zároveň opakovat názvy technologií.“
Vygenerovaný text jsem poté vložil do souboru s názvem tech.txt, který budeme dále v tutoriálu používat.
Nakonec, nezbytná je i základní znalost příkazu grep. Pro osvěžení si můžete projít našich 16 příkladů použití příkazu grep. Pro začátek si ale grep krátce představíme.
Syntaxe a příklady příkazu grep
Syntaxe příkazu grep je poměrně jednoduchá:
$ grep -options [regex/pattern] [files]Jak vidíte, příkaz očekává vzor a seznam souborů, ve kterých se má vyhledávat.
Existuje mnoho možností (options), které ovlivňují chování příkazu grep. Mezi ně patří:
-i: Ignorování velikosti písmen-r: Rekurzivní prohledávání-w: Vyhledávání pouze celých slov-v: Zobrazení všech řádků, které danému vzoru neodpovídají-n: Zobrazení čísel odpovídajících řádků-l: Zobrazení pouze názvů souborů, které obsahují hledaný vzor--color: Barevné zvýraznění výstupu-c: Zobrazení počtu shod pro daný vzor
#1. Vyhledávání celého slova
Pro vyhledávání celého slova je třeba použít argument -w. Tím zajistíte, že se budou hledat pouze řetězce, které přesně odpovídají zadanému vzoru.
$ grep -w ‘tech\|5G’ tech.txtVýsledkem příkazu je výstup, který hledá slova "5G" a "tech" v celém textu a zvýrazní je červenou barvou.
Symbol | (svislá čára) je v tomto případě chápán jako "nebo" a je třeba ho "escapovat" (předřadit zpětné lomítko), aby jej grep nezpracoval jako metaznak.
#2. Vyhledávání bez rozlišování velikosti písmen
Pro vyhledávání, které nerozlišuje velikost písmen, použijte příkaz grep s argumentem -i.
$ grep -i ‘tech’ tech.txtTento příkaz najde všechny instance řetězce "tech", bez ohledu na velikost písmen, ať už se jedná o celé slovo nebo jeho část.
#3. Vyhledávání neodpovídajících řádků
Pokud potřebujete zobrazit všechny řádky, které neobsahují daný vzor, použijte argument -v.
$ grep -v ‘tech’ tech.txt
Výstup ukazuje všechny řádky, které neobsahují slovo "tech". Jsou zde vidět i prázdné řádky, které se nacházejí za odstavci.
#4. Rekurzivní vyhledávání
Pro rekurzivní vyhledávání, tedy prohledávání i podadresářů, použijte argument -r.
$ grep -R ‘error\|warning’ /var/log/*.log#output
/var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1]
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!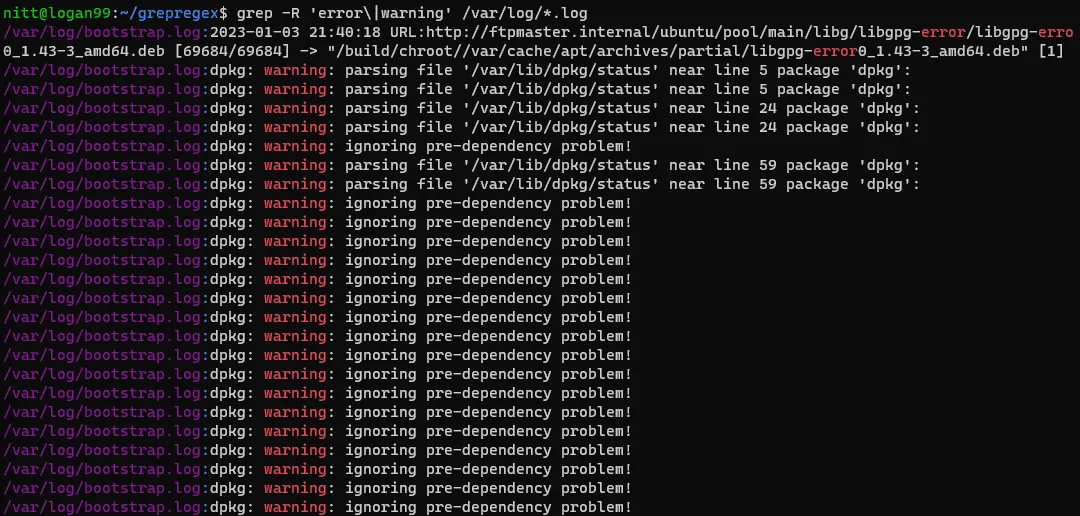
Tento příkaz rekurzivně vyhledává slova "error" a "warning" v adresáři /var/log. Je to velice užitečné pro nalezení všech varování a chyb v logovacích souborech.
Grep a Regex: Co to je a příklady
Při práci s regulárními výrazy je důležité si uvědomit, že existují tři varianty syntaxe:
- Základní regulární výrazy (BRE)
- Rozšířené regulární výrazy (ERE)
- Regulární výrazy kompatibilní s jazykem Perl (PCRE)
Příkaz grep používá ve výchozím nastavení BRE. Chcete-li tedy použít jiný režim regulárních výrazů, musíte to explicitně uvést. Příkaz grep také zachází s metaznaky jako s běžnými znaky. Pokud chcete použít metaznaky jako ?, +, ), je potřeba předřadit jim zpětné lomítko (\).
Syntaxe příkazu grep s regulárními výrazy vypadá takto:
$ grep [regex] [filenames]Podívejme se na praktické příklady použití příkazu grep s regulárními výrazy.
#1. Doslovné shody slov
Pro doslovnou shodu slov stačí zadat řetězec jako regulární výraz. I slovo je totiž také regulární výraz.
$ grep "technologies" tech.txt
Stejným způsobem můžete hledat i aktivní uživatele. Stačí spustit příkaz:
$ grep bash /etc/passwd#output
root:x:0:0:root:/root:/bin/bash
nitt:x:1000:1000:,,,:/home/nitt:/bin/bash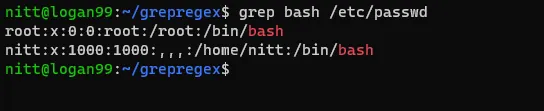
Výstup zobrazí uživatele, kteří mají přístup k shellu bash.
#2. Porovnávání kotev
Porovnávání kotev je užitečná technika pro pokročilé vyhledávání pomocí speciálních znaků. V regulárních výrazech existují různé kotevní znaky, které se používají k určení konkrétních pozic v textu. Mezi tyto znaky patří:
- Symbol stříšky (
^): Symbol stříšky odpovídá začátku vstupního řetězce nebo řádku a vyhledává prázdný řetězec. - Symbol dolaru (
$): Symbol dolaru odpovídá konci vstupního řetězce nebo řádku a vyhledává prázdný řetězec.
Další dva kotevní znaky jsou hranice slova (\b) a hranice neslova (\B).
- Hranice slova (
\b): Pomocí\bmůžete ověřit pozici mezi slovem a ne-slovním znakem. Jednoduše řečeno, umožňuje to porovnávat celá slova. Tímto způsobem se vyhnete částečným shodám. Také ho můžete využít k nahrazování slov nebo pro počítání výskytů slov v řetězci. - Hranice neslova (
\B): Je to opak hranice slova\bv regulárním výrazu, protože vynucuje pozici, která není mezi dvěma slovy nebo ne-slovními znaky.
Pojďme se podívat na příklady pro lepší pochopení.
$ grep ‘^From’ tech.txt
Použití symbolu stříšky vyžaduje zadat slovo nebo vzor ve správné velikosti písmen, protože rozlišuje malá a velká písmena. Pokud spustíte následující příkaz, nic se nenajde:
$ grep ‘^from’ tech.txtPodobně můžete použít symbol $ k nalezení řetězce, který odpovídá zadanému vzoru na konci řádku.
$ grep ‘technology.$' tech.txt
Je možné kombinovat symboly ^ a $. Podívejme se na následující příklad:
$ grep “^From \| technology.$” tech.txt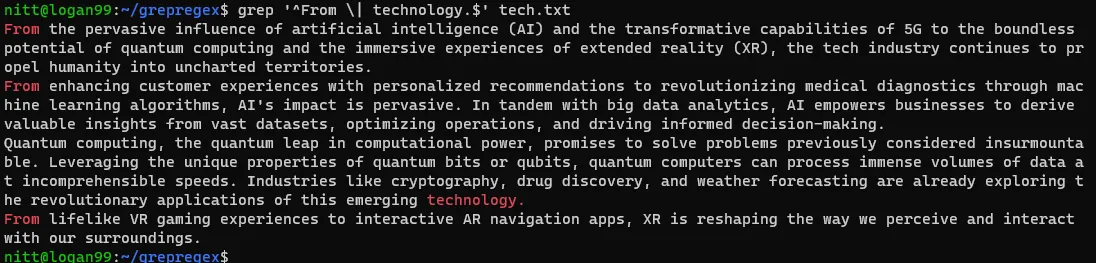
Jak vidíte, výstup obsahuje řádky, které začínají na "From" a řádky, které končí na "technology".
#3. Seskupování
Chcete-li najednou vyhledávat více vzorů, musíte použít seskupování. To vám pomůže vytvářet malé skupiny znaků a vzorů, se kterými můžete pracovat jako s jednou entitou. Můžete například vytvořit skupinu (tech), která bude obsahovat znaky 't', 'e', 'c', a 'h'.
Podívejme se na příklad pro lepší pochopení:
$ grep 'technol\(ogy\)\?' tech.txt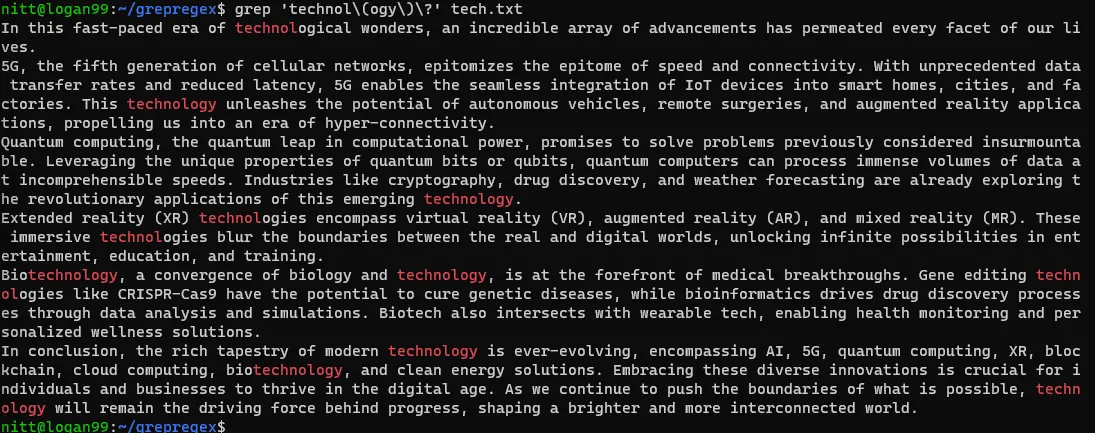
Pomocí seskupování můžete porovnávat opakující se vzory, zachycovat skupiny a vyhledávat alternativy.
Alternativní vyhledávání se seskupováním
Podívejme se na příklad alternativního vyhledávání.
$ grep "\(tech\|technology\)" tech.txt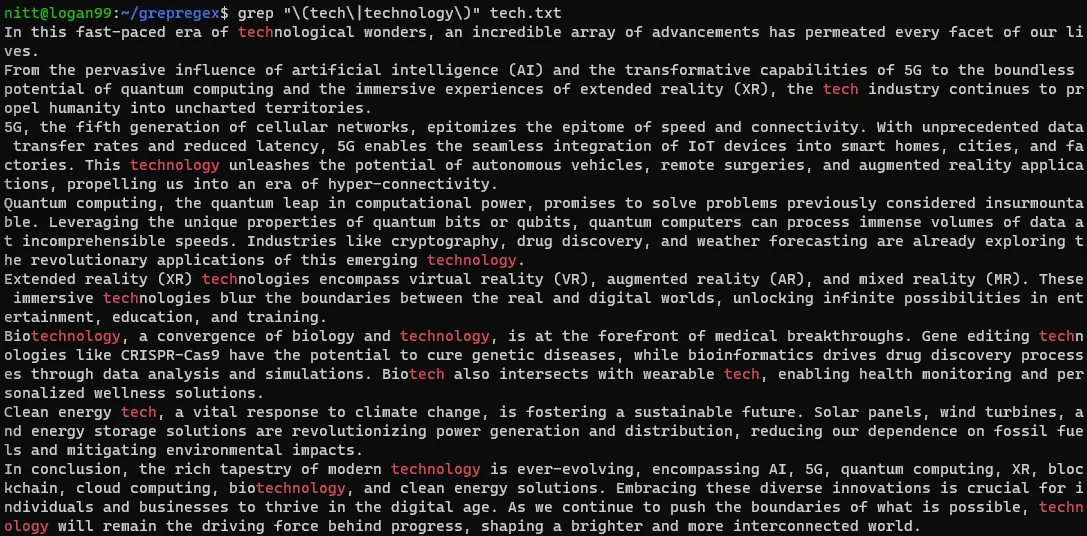
Pokud chcete vyhledávat v řetězci, je třeba ho předat se symbolem svislé čáry. Podívejme se na následující příklad.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"#output
“tech technological technologies technical”
Zachycení skupin, nezachycení skupin a opakující se vzory
Jak je to se zachycením a nezachycením skupin?
Pro zachycení skupin je třeba v regulárním výrazu vytvořit skupinu a předat ji řetězci nebo souboru.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"#output
tech655 tech655nical technologies655 tech655-oriented 655
Pro nezachycení skupiny je potřeba použít ?: v závorkách.
Nakonec se podíváme na opakující se vzory. Pro vyhledávání opakujících se vzorů je třeba upravit regulární výraz.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'#output
‘teach tech ttrial tttechno attest’Tento regulární výraz vyhledává jeden nebo více výskytů znaku 't'.
#4. Třídy znaků
S třídami znaků můžete snadno psát výrazy regulárních výrazů. Tyto třídy znaků používají hranaté závorky. Mezi známé třídy znaků patří:
[:digit:]– číslice 0 až 9[:alpha:]– abecední znaky[:alnum:]– alfanumerické znaky[:lower:]– malá písmena[:upper:]– velká písmena[:xdigit:]– hexadecimální číslice, včetně 0-9, A-F, a-f[:blank:]– prázdné znaky, jako je tabulátor nebo mezera
A tak dále!
Podívejme se na několik příkladů:
$ grep [[:digit]] tech.txt
$ grep [[:alpha:]] tech.txt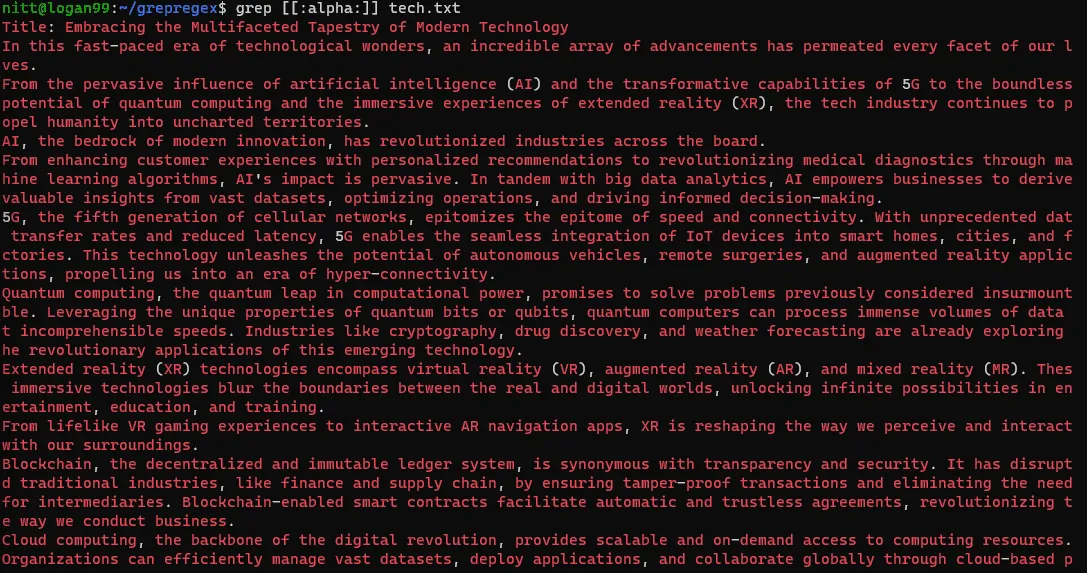
$ grep [[:xdigit:]] tech.txt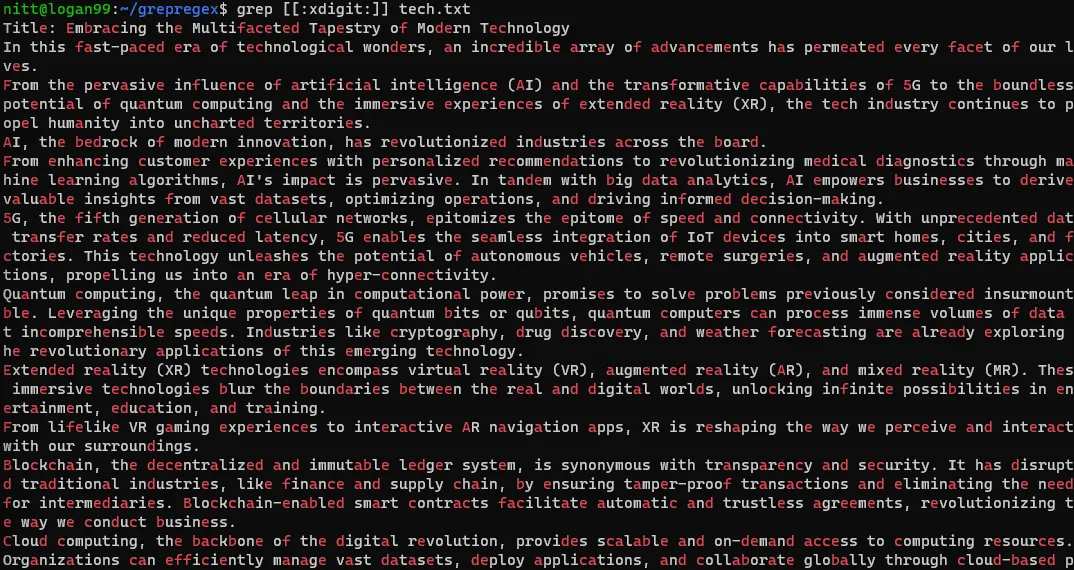
#5. Kvantifikátory
Kvantifikátory jsou metaznaky, které tvoří jádro regulárního výrazu. Pomocí nich lze přesně definovat počet výskytů. Mezi kvantifikátory patří:
*→ Nula nebo více shod+→ Jedna nebo více shod?→ Shoda nula nebo jedna{x}→ Odpovídá x{x, }→ x nebo více shod{x,z}→ Od x do z shod{, z}→ Až z shod
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'#output
‘teach tech ttrial tttechno attest’Tento příkaz hledá výskyty znaku 't' pro jednu nebo více shod. Zde -E znamená rozšířený regulární výraz (o kterém budeme hovořit dále).

#6. Rozšířený Regex
Pokud nechcete přidávat escape znaky do regulárních výrazů, musíte použít rozšířený regulární výraz. Ten odstraňuje potřebu přidávat escape znaky. Chcete-li ho použít, je potřeba použít parametr -E.
$ grep -E 'in+ovation' tech.txt
#7. Použití PCRE pro komplexní vyhledávání
PCRE (Perl Compatible Regular Expression) umožňuje daleko více než jen psát základní výrazy. Můžete například použít výraz \d, který odpovídá výrazu [0-9].
Pomocí PCRE můžete například vyhledávat e-mailové adresy:
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"#output
Contact me at [email protected]
Zde PCRE zajistí shodu vzoru. Podobně můžete použít vzor PCRE ke kontrole formátů dat.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"#output
The Sparkain site launched on 2023-07-29
Tento příkaz hledá datum ve formátu RRRR-MM-DD. Je možné ho upravit pro jiný formát dat.
#8. Střídání
Pro alternativní shody můžete použít symbol svislé čáry (\|).
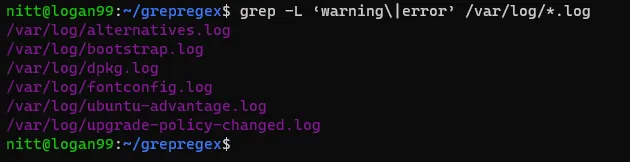
$ grep -L ‘warning\|error’ /var/log/*.log#output
/var/log/alternatives.log
/var/log/bootstrap.log
/var/log/dpkg.log
/var/log/fontconfig.log
/var/log/ubuntu-advantage.log
/var/log/upgrade-policy-changed.logVýstup zobrazuje názvy souborů, které obsahují slova "warning" nebo "error".
Závěrečná slova
Tímto se dostáváme na konec našeho průvodce příkazem grep a regulárními výrazy. Grep s regulárními výrazy je mocný nástroj pro upřesnění vyhledávání. Při správném použití můžete ušetřit spoustu času a zautomatizovat mnoho úkolů, zejména pokud grep využíváte pro psaní skriptů nebo při procházení textu.
Nakonec se podívejte na časté otázky a odpovědi na pohovorech na Linuxu.
