Jak jsou datové trezory budoucností datových skladů[+5 Learning Resources]
S narůstajícím objemem dat generovaných firmami se tradiční přístupy k datovým skladům stávají stále náročnějšími a jejich údržba je čím dál dražší. Data Vault, relativně nový koncept v oblasti datových skladů, přichází s řešením tohoto problému. Nabízí totiž škálovatelný, flexibilní a ekonomicky efektivní způsob, jak spravovat obrovská množství dat.
V tomto článku se podíváme na to, proč se Data Vault stává budoucností datového skladování a proč stále více organizací přechází k tomuto přístupu. Zároveň poskytneme zdroje pro ty, kteří chtějí proniknout do tohoto tématu hlouběji!
Co je Data Vault?
Data Vault je metodika modelování datových skladů, která se obzvláště hodí pro agilní datové sklady. Vyznačuje se vysokou flexibilitou při rozšiřování, kompletní časovou historizací dat a umožňuje paralelní zpracování při načítání dat. Dan Linstedt vyvinul modelování Data Vault v 90. letech.
Po prvním zveřejnění v roce 2000 se konceptu dostalo větší pozornosti v roce 2002 díky sérii článků. V roce 2007 získal Linstedt podporu Billa Inmona, který jej označil za "optimální volbu" pro svou architekturu Data Vault 2.0.
Každý, kdo se zabývá myšlenkou agilního datového skladu, dříve či později narazí na Data Vault. Tato technologie je specifická tím, že je zaměřena na potřeby společností a umožňuje flexibilní úpravy datového skladu s nízkými náklady.
Data Vault 2.0 zohledňuje celý proces vývoje i architekturu a skládá se z metody (implementace), architektury a samotného modelu. Výhodou je, že tento přístup při vývoji zahrnuje všechny aspekty business intelligence se základním datovým skladem.
Model Data Vault nabízí moderní řešení pro překonání omezení tradičních přístupů k modelování dat. Díky své škálovatelnosti, flexibilitě a agilitě vytváří pevný základ pro budování datové platformy, která se dokáže přizpůsobit složitosti a různorodosti moderních datových prostředí.
Architektura "hub-and-spoke" a oddělení entit a atributů v Data Vault umožňují integraci a harmonizaci dat napříč různými systémy a doménami. To zjednodušuje postupný a agilní vývoj.
Klíčovou rolí Data Vault při budování datové platformy je vytvoření jednotného zdroje pravdy pro všechna data. Jeho jednotný pohled na data a podpora pro zachycování a sledování historických změn dat prostřednictvím satelitních tabulek umožňuje audit, dodržování regulatorních požadavků a komplexní analýzu a reporting.
Schopnosti datové integrace Data Vault téměř v reálném čase pomocí delta načítání usnadňují práci s velkými objemy dat v rychle se měnících prostředích, jako jsou aplikace Big Data a IoT.
Data Vault vs. tradiční modely datových skladů
Třetí normální forma (3NF) je jedním z nejznámějších tradičních modelů datových skladů, často používaným v mnoha rozsáhlých implementacích. Tento model odpovídá myšlenkám Billa Inmona, jednoho z "otců" konceptu datového skladu.
Inmonova architektura vychází z relačního databázového modelu a eliminuje redundanci dat rozdělením datových zdrojů do menších tabulek, které jsou uloženy v datových tržištích a jsou propojeny pomocí primárních a cizích klíčů. Zajišťuje tak konzistenci a přesnost dat díky vynucování pravidel referenční integrity.
Cílem normální formy bylo vybudovat komplexní podnikový datový model pro základní datový sklad. Nicméně má problémy se škálovatelností a flexibilitou kvůli vysoce propojeným datovým trhům, potížím s načítáním v reálném čase, náročným požadavkům na návrh a implementaci shora dolů.
Kimballův model, používaný pro OLAP (online analytické zpracování) a datová tržiště, je dalším známým modelem datového skladu. V něm tabulky faktů obsahují agregovaná data a tabulky dimenzí popisují uložená data ve hvězdicovém nebo sněhovém schématu. V této architektuře jsou data organizována do tabulek faktů a dimenzí, které jsou denormalizovány pro zjednodušení dotazování a analýzy.
Kimball vychází z dimenzionálního modelu, který je optimalizován pro dotazování a generování reportů. Proto je ideální pro aplikace business intelligence. Má ale problémy s izolací předmětově orientovaných informací, redundancí dat, nekompatibilními strukturami dotazů, problémy se škálovatelností, nekonzistentní granularitou tabulek faktů, problémy se synchronizací a potřebou návrhu shora dolů s implementací zdola nahoru.
Architektura Data Vault je oproti tomu hybridním přístupem, který kombinuje aspekty architektur 3NF i Kimball. Jde o model založený na relačních principech, normalizaci dat a redundantní matematice, který odlišně reprezentuje vztahy mezi entitami a odlišně strukturuje pole tabulek a časová razítka.
V této architektuře jsou všechna data uložena v trezoru nezpracovaných dat nebo v datovém jezeře. Běžně používaná data jsou pak uložena v normalizovaném formátu v obchodním trezoru. Ten obsahuje historická a kontextově specifická data, která lze použít pro vytváření sestav.
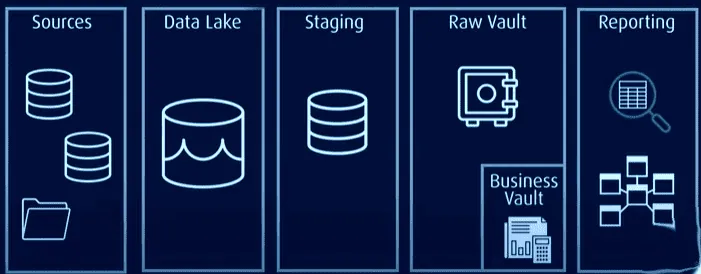
Data Vault řeší problémy tradičních modelů tím, že je efektivnější, škálovatelnější a flexibilnější. Umožňuje načítání téměř v reálném čase, lepší integritu dat a snadné rozšiřování bez vlivu na stávající struktury. Model lze také rozšířit bez nutnosti migrace stávajících tabulek.
| Přístup k modelování | Struktura dat | Přístup k návrhu |
| 3NF | Modelovací tabulky 3NF | Zdola nahoru |
| Kimball | Modelování hvězdicového nebo sněhového schématu | Shora dolů |
| Data Vault | Kombinace 3NF a dimenzionálního modelování | Zdola nahoru s prvkem shora dolů |
Architektura Data Vault
Data Vault má architekturu "hub-and-spoke" a skládá se ze tří základních vrstev:
Staging Layer: Shromažďuje nezpracovaná data ze zdrojových systémů, jako jsou CRM nebo ERP.
Vrstva datového skladu: V modelování Data Vault tato vrstva zahrnuje:
- Raw Data Vault: Ukládá nezpracovaná data.
- Business Data Vault: Obsahuje harmonizovaná a transformovaná data založená na obchodních pravidlech (volitelné).
- Vault metrik: Ukládá informace o běhu (volitelné).
- Operational Vault: Ukládá data, která proudí přímo z operačních systémů do datového skladu (volitelné).
Vrstva Data Mart: Tato vrstva modeluje data do hvězdicového schématu nebo používá jiné modelovací techniky. Poskytuje data pro analýzu a reportování.
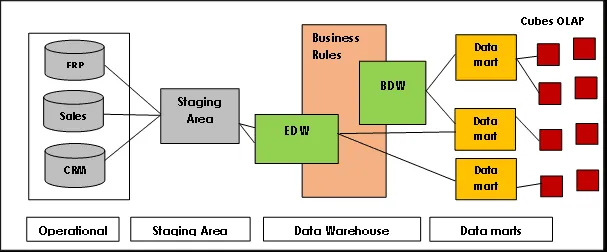 Zdroj obrázku: Lamia Yessad
Zdroj obrázku: Lamia Yessad
Data Vault nevyžaduje kompletní re-architekturu. Nové funkce lze budovat paralelně s využitím konceptů a metod Data Vault, aniž by docházelo ke ztrátě stávajících komponent. Frameworky mohou výrazně usnadnit práci: tvoří mezivrstvu mezi datovým skladem a vývojářem a snižují tak složitost implementace.
Komponenty Data Vault
Při modelování Data Vault rozděluje veškeré informace patřící k objektu do tří kategorií, na rozdíl od klasického modelování třetí normální formy. Tyto informace jsou pak uloženy odděleně od sebe. Funkční oblasti lze v Data Vault mapovat pomocí tzv. center (hub), linků a satelitů:
#1. Centra (Hubs)
Centra jsou jádrem základních obchodních konceptů, jako je zákazník, prodejce, prodej nebo produkt. Tabulka centra je vytvořena kolem obchodního klíče (název obchodu nebo umístění), když je do datového skladu poprvé zavedena nová instance tohoto obchodního klíče.
Centrum neobsahuje žádné popisné informace ani cizí klíče. Skládá se pouze z obchodního klíče s interně vygenerovanou sekvencí ID nebo hash klíčů, razítkem data/času načtení a zdrojem záznamů.
#2. Linky
Linky vytvářejí vztahy mezi obchodními klíči. Každý záznam v lince modeluje vztahy N:M mezi libovolným počtem center. To umožňuje Data Vault pružně reagovat na změny v obchodní logice zdrojových systémů, jako jsou změny v počtu vztahů. Stejně jako centra ani linky neobsahují žádné popisné informace. Skládají se z ID sekvencí center, na které odkazují, interně vygenerované ID sekvence, razítka data/času načtení a zdroje záznamů.
#3. Satelity
Satelity obsahují popisné informace (kontext) pro obchodní klíč uložený v centru nebo vztah uložený v lince. Satelity fungují na principu "pouze vložení", což znamená, že kompletní historie dat je uložena v satelitu. Jeden obchodní klíč (nebo vztah) může popisovat více satelitů. Satelit však může popisovat pouze jeden klíč (centrum nebo linku).
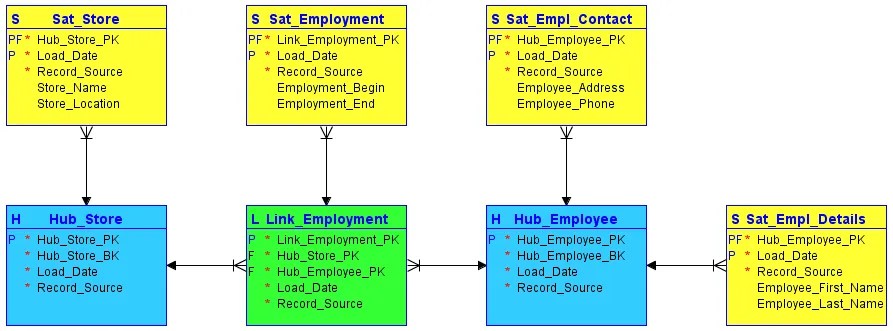 Zdroj obrázku: Carbidfischer
Zdroj obrázku: Carbidfischer
Jak vytvořit model Data Vault
Vytvoření modelu Data Vault zahrnuje několik kroků, z nichž každý je zásadní pro zajištění škálovatelnosti, flexibility a schopnosti splnit potřeby podniku:
#1. Identifikujte entity a atributy
Identifikujte podnikatelské subjekty a jejich odpovídající atributy. Zahrnuje úzkou spolupráci s obchodními partnery, abychom porozuměli jejich požadavkům a datům, která potřebují zachytit. Jakmile jsou tyto entity a atributy identifikovány, rozdělte je na centra, linky a satelity.
#2. Definujte vztahy entit a vytvořte linky
Po identifikaci entit a atributů definujte vztahy mezi entitami a vytvořte linky, které tyto vztahy reprezentují. Každé lince je přiřazen obchodní klíč, který identifikuje vztah mezi entitami. Satelity se následně přidají k zachycení atributů a vztahů entit.
#3. Stanovte pravidla a standardy
Po vytvoření linků by měla být stanovena sada pravidel a standardů pro modelování Data Vault, aby bylo zajištěno, že model bude flexibilní a zvládne změny v průběhu času. Tato pravidla a standardy by měly být pravidelně kontrolovány a aktualizovány, aby zůstaly relevantní a odpovídaly obchodním potřebám.
#4. Naplňte model
Jakmile byl model vytvořen, měl by být naplněn daty pomocí přístupu inkrementálního načítání. Zahrnuje načítání dat do center, linků a satelitů pomocí delta načítání. Delta načítání zajistí, že budou načteny pouze změny provedené v datech, čímž se zkrátí čas a zdroje potřebné pro integraci dat.
#5. Otestujte a ověřte model
Nakonec by měl být model otestován a ověřen, aby bylo zajištěno, že splňuje obchodní požadavky a je dostatečně škálovatelný a flexibilní pro zvládnutí budoucích změn. Je třeba provádět pravidelnou údržbu a aktualizace, aby model zůstal v souladu s obchodními potřebami a nadále poskytoval jednotný pohled na data.
Výukové zdroje pro Data Vault
Získání dovedností a znalostí v oblasti Data Vault může být velmi cenné, protože je v dnešním datově orientovaném průmyslu velká poptávka. Zde je úplný seznam zdrojů, včetně kurzů a knih, které vám mohou pomoci naučit se složitosti Data Vault:
#1. Modelování datového skladu pomocí Data Vault 2.0

Tento kurz na Udemy je komplexním úvodem do modelovacího přístupu Data Vault 2.0, agilního řízení projektů a integrace velkých dat. Kurz pokrývá základy Data Vault 2.0, včetně jeho architektury a vrstev, obchodních a informačních trezorů a pokročilých modelovacích technik.
Naučí vás, jak navrhnout model Data Vault od začátku, převést tradiční modely jako 3NF a dimenzionální modely na Data Vault a porozumět principům dimenzionálního modelování v Data Vault. Kurz vyžaduje základní znalost databází a základů SQL.
S vysokým hodnocením 4,4 z 5 a více než 1 700 recenzemi je tento kurz vhodný pro každého, kdo si chce vybudovat pevné základy v Data Vault 2.0 a integraci Big Data.
#2. Modelování datového trezoru vysvětleno s případem použití

Tento kurz na Udemy vás provede procesem vytvoření modelu Data Vault pomocí praktického obchodního příkladu. Slouží jako průvodce pro začátečníky v modelování Data Vault a zahrnuje klíčové koncepty, jako jsou vhodné scénáře pro použití modelů Data Vault, omezení konvenčního modelování OLAP a systematický přístup ke konstrukci modelu Data Vault. Kurz je přístupný i pro osoby s minimálními znalostmi databází.
#3. The Data Vault Guru: Pragmatický průvodce
"Data Vault Guru" od Patricka Cuby je komplexní průvodce metodologií Data Vault. Nabízí jedinečnou příležitost modelovat podnikový datový sklad pomocí principů automatizace podobných těm, které se používají při vývoji softwaru.
Kniha poskytuje přehled moderní architektury a následně nabízí detailní návod, jak dodat flexibilní datový model, který se přizpůsobí změnám v podniku – Data Vault.
Kniha navíc rozšiřuje metodiku Data Vault tím, že poskytuje automatické opravy časové osy, auditní záznamy, kontrolu metadat a integraci s agilními nástroji pro vývoj.
#4. Vybudování škálovatelného datového skladu s Data Vault 2.0
Tato kniha poskytuje čtenářům komplexního průvodce pro vytvoření škálovatelného datového skladu od začátku do konce s využitím metodologie Data Vault 2.0.
Kniha pokrývá všechny základní aspekty budování škálovatelného datového skladu, včetně techniky modelování Data Vault, která je navržena tak, aby předešla typickým problémům datových skladů.
Kniha obsahuje mnoho příkladů, které čtenářům pomohou jasně pochopit dané pojmy. Díky praktickým poznatkům a příkladům z reálného světa je tato kniha nepostradatelným zdrojem pro každého, kdo se zajímá o datové sklady.
#5. Slon v lednici: Řízené kroky k úspěchu v Data Vault
"Slon v lednici" od Johna Gilese je praktická příručka, jejímž cílem je pomoci čtenářům dosáhnout úspěchu s Data Vault. Klade důraz na podnikání a jeho role v celém procesu.
Kniha se zaměřuje na důležitost podnikové ontologie a modelování obchodních konceptů a poskytuje podrobný návod, jak tyto koncepty aplikovat při tvorbě solidního datového modelu.
Autor nabízí jasné a srozumitelné vysvětlení komplikovaných témat pomocí praktických rad a vzorových modelů, což z této knihy činí vynikajícího průvodce pro ty, kteří s Data Vault začínají.
Závěrem
Data Vault představuje budoucnost datových skladů a společnostem nabízí významné výhody z hlediska flexibility, škálovatelnosti a efektivity. Je zvláště vhodný pro podniky, které potřebují rychle načítat velké objemy dat, a pro ty, které chtějí vyvíjet své aplikace business intelligence agilním způsobem.
Společnosti s existujícími silovými architekturami navíc mohou výrazně profitovat z implementace základního datového skladu pomocí Data Vault.
Možná vás také bude zajímat informace o datové řadě.
