Jak používat příkaz look v systému Linux
Příkaz look v Linuxu slouží k prohledávání souborů a zobrazení řádků, které začínají zadaným slovem nebo frází. Je však důležité si uvědomit, že jeho chování se může lišit napříč různými distribucemi Linuxu. Tento návod vám ukáže, jak s ním pracovat efektivně.
Rozdíly v chování příkazu look v Ubuntu
Při zkoumání tohoto, na první pohled jednoduchého příkazu, jsem narazil na dva klíčové problémy: rozdíly v implementaci a nedostatečnou dokumentaci. Článek byl testován v distribucích Ubuntu, Fedora a Manjaro, kde byl příkaz look přítomen ve všech. Problém však spočíval v rozdílném chování příkazu v Ubuntu oproti ostatním distribucím. Podle oficiálních manuálových stránek Ubuntu by se chování mělo shodovat, nicméně praxe ukázala něco jiného.
Zásadní rozdíl spočívá v tom, že tradičně příkaz look využívá binární vyhledávání, zatímco verze v Ubuntu používá lineární vyhledávání. Ačkoliv online manuálové stránky pro Ubuntu (verze 18.04, 18.10 a 19.04) tvrdí opak, lokální manuálové stránky v Ubuntu správně uvádějí, že je použito lineární vyhledávání. Existuje nicméně přepínač, kterým lze vynutit binární vyhledávání. V ostatních distribucích možnost volby mezi metodami vyhledávání nenajdeme.
man look
Prohlédnutím lokální manuálové stránky můžeme jasně vidět část, která popisuje použití lineárního vyhledávání.
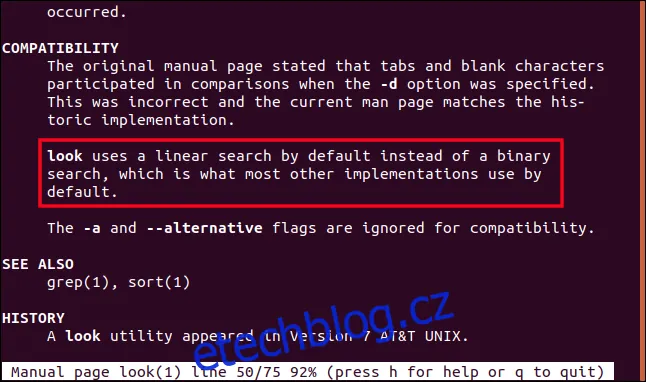
Závěrem lze tedy říci, že je vždy důležité kontrolovat lokální manuálové stránky.
Lineární vs. binární vyhledávání
Binární vyhledávání je obecně rychlejší a efektivnější než lineární. Rozdíl je nejvíce znát při práci s velkými soubory. Nicméně binární vyhledávání vyžaduje, aby byl prohledávaný soubor seřazen. Pokud jej nechcete seřadit, můžete si vytvořit seřazenou kopii a s tou pracovat.
Tuto metodu si ukážeme později. Prozatím si pamatujte, že na Fedoře, Manjaru a většině ostatních distribucí Linuxu budete pravděpodobně muset vytvořit seřazenou kopii pro efektivní práci s příkazem look.
Instalace slovníku
Příkaz look může prohledávat libovolný textový soubor, včetně souboru se slovy "words", který slouží jako systémový slovník.
V Manjaru je potřeba tento soubor nainstalovat. Použijte následující příkaz:
sudo pacman -Syu words

Základní použití příkazu look
V tomto návodu si ukážeme práci s textem básně Edwarda Leara s názvem "The Jumblies".
Prohlédneme si obsah tohoto souboru pomocí příkazu:
less the-jumblies.txt

Zde je úryvek básně. Vzhledem k tomu, že používáme Ubuntu, pracujeme s neseřazeným souborem. V případě Fedory a Manjara by bylo nutné pracovat s seřazenou kopií, jak si ukážeme později.

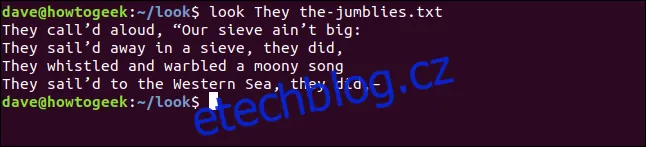
Pokud chceme vyhledat všechny řádky, které začínají slovem "oni", získáme přehled o tom, co Jumblies prováděli:
look They the-jumblies.txt

Příkaz look nám vrátí tyto řádky:
Ignorování velikosti písmen
Pro ignorování rozdílu mezi velkými a malými písmeny použijte volbu -f (ignore case). Opět použijeme hledané slovo "oni", ale tentokrát s malým počátečním písmenem.
look -f they the-jumblies.txt

Výsledky nyní zahrnují jeden řádek navíc:
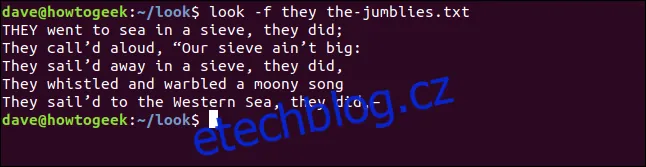
Řádek začínající "ONI" byl v předchozích výsledcích vynechán, protože byl celý napsán velkými písmeny. Ignorování velikosti písmen nám umožňuje tento řádek do výsledků zahrnout.
Použití příkazu look se seřazeným souborem
Pokud vaše distribuce Linuxu používá tradiční verzi příkazu look s binárním vyhledáváním, musíte buď seřadit soubor, nebo použít jeho seřazenou kopii.
Zopakujme hledání slova "Oni", tentokrát na Manjaru.

Jak vidíte, nebyly vráceny žádné výsledky. Přitom víme, že v básni jsou řádky začínající "Oni".
Vytvořme tedy seřazenou kopii. Pokud chcete použít volby -f (ignorovat velikost písmen) nebo -d (pouze alfanumerické znaky a mezery) s příkazem look, musíte tyto volby použít i při třídění souboru.
Volba -o (output) nám umožňuje definovat název souboru, do kterého se mají uložit setříděné řádky, v tomto případě "sorted.txt".
sort -f -d the-jumblies.txt -o sorted.txt

Nyní zkusíme použít příkaz look na soubor "sorted.txt", tentokrát s volbami -f a -d:
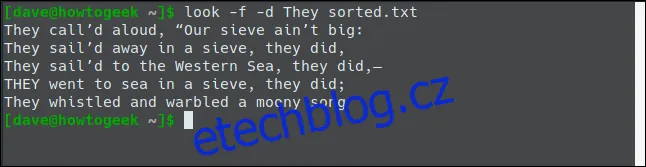
Nyní dostáváme očekávané výsledky.
Omezení se na alfanumerické znaky a mezery
Pokud chcete, aby příkaz look ignoroval vše, co není alfanumerický znak nebo mezera, použijte volbu -d (alphanumeric).
Zkusme vyhledat slova začínající na "Ach".
look -f oh the-jumblies.txt

Příkaz nevrátil žádné výsledky.
Zkusme to znovu a řekněme look, aby ignoroval cokoliv kromě alfanumerických znaků a mezer, tedy i interpunkci a symboly.
look -f -d oh the-jumblies.txt

Tentokrát dostáváme výsledek. Dříve jsme tento řádek nenašli, protože uvozovky a vykřičník narušovaly hledání.

Definování ukončovacího znaku
Příkazu look můžete také nastavit konkrétní znak, který se bude brát jako ukončovací. Standardně se jako ukončovací znaky používají mezery a konce řádků.
Volba -t (terminating character) nám umožňuje specifikovat vlastní znak. V tomto příkladu použijeme apostrof. Ten musíme uvést s únikovým znakem (zpětné lomítko), aby look neinterpretoval apostrof jako začátek řetězce.
Hledaný výraz také musíme uvést v uvozovkách, protože obsahuje mezeru, a hledáme tedy dvě slova.
look -f -t \' "they call" the-jumblies.txt

Výsledky odpovídají hledanému výrazu, který končí apostrofem, který jsme si zvolili jako ukončovací znak.

Použití příkazu look bez souboru
Pokud v příkazu nezadáte název souboru, použije look systémový slovník.
Zkusíme například příkaz:

výsledkem budou následující slova:
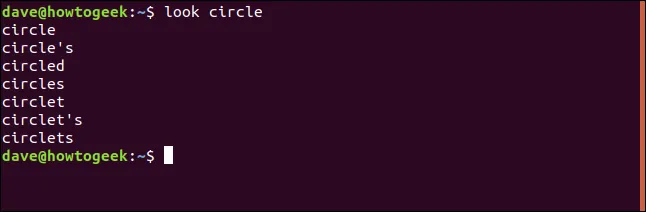
Jedná se o všechna slova v systému, která začínají na "kruh".
Závěrem
To je vše, co potřebujete vědět o příkazu look.
Jakmile pochopíte, že chování se může lišit mezi distribucemi a zjistíte, jestli vaše verze používá binární nebo lineární vyhledávání, je práce s ním poměrně jednoduchá.
