Pravděpodobně nejlepší alternativa k úložišti CSV: Parketová data
Výhody formátu Apache Parquet pro ukládání dat
Formát Apache Parquet nabízí oproti tradičním metodám, jako je CSV, řadu výhod při ukládání a načítání dat. Jeho konstrukce je optimalizována pro rychlé zpracování dat s komplexní strukturou. V tomto článku se podíváme, proč je Parquet tak vhodný pro současné narůstající objemy dat.
Než se pustíme do detailů formátu Parquet, je důležité porozumět tomu, jak funguje ukládání dat ve formátu CSV a jaké s ním souvisejí potíže.
Co je to CSV?
Formát CSV (Comma Separated Values), neboli hodnoty oddělené čárkami, je všeobecně známý způsob organizace a formátování dat. Data v CSV jsou ukládána v řádcích, přičemž soubory mají příponu .csv. CSV soubory lze snadno otevírat a prohlížet v aplikacích jako Excel, Google Tabulky, nebo jakémkoli textovém editoru. Po otevření souboru je datová struktura okamžitě viditelná.
Nicméně, tento jednoduchý formát není ideální pro databázové účely.
S nárůstem objemu dat se stává obtížnější data efektivně dotazovat, spravovat a získávat.
Následující příklad ukazuje data uložená v souboru .CSV:
EmpId,Jméno,Příjmení,Oddělení
2012011,Sam,Butcher,IT
2013031,Mike,Johnson,Lidské zdroje
2010052,Bill,Matthew,Architekt
2010079,Jose,Brian,IT
2012120,Adam,James,Řešení
Při zobrazení v aplikaci Excel uvidíme tabulkovou strukturu s řádky a sloupci, jak je uvedeno níže:
Problémy s CSV
Ukládání dat založené na řádcích, jako je CSV, je vhodné pro operace vytváření, aktualizace a mazání. Ale co operace čtení (Read) v CRUD?
Představte si milion řádků v souboru .csv. Otevření takového souboru a vyhledávání konkrétních dat by trvalo dlouho, což není ideální. Mnoho cloudových poskytovatelů, jako například AWS, účtuje poplatky na základě objemu skenovaných nebo uložených dat, a CSV soubory zabírají hodně místa.
Další nevýhodou CSV je nemožnost ukládat metadata, takže skenování dat je zdlouhavý proces.
Jaké je tedy nákladově efektivní a optimální řešení pro efektivní provádění všech operací CRUD? Pojďme se na to podívat.
Co je formát Parquet?
Parquet je formát úložiště dat s otevřeným zdrojovým kódem. Je široce využíván v ekosystémech Hadoop a Spark. Soubory Parquet mají příponu .parquet.
Parquet je vysoce strukturovaný formát. Je optimalizován pro efektivní zpracování velkých objemů surových dat v datových jezerech. Tím se výrazně zkracuje doba potřebná k dotazování dat.
Parquet umožňuje efektivní ukládání dat a rychlé načítání díky kombinaci řádkového a sloupcového (hybridního) formátu. Data jsou rozdělena horizontálně i vertikálně, což minimalizuje režii při analýze dat.
Tento formát snižuje celkový počet I/O operací a v důsledku toho i náklady.
Parquet také ukládá metadata, která obsahují informace o datech, jako je datové schéma, počet hodnot, umístění sloupců, minimální a maximální hodnoty, počet skupin řádků a typy kódování. Metadata jsou uložena v souboru na různých úrovních, což urychluje přístup k datům.
V řádkovém přístupu, jako je CSV, trvá načítání dat dlouho, protože dotaz musí projít každý řádek, aby získal hodnoty konkrétního sloupce. S formátem Parquet je možné přistupovat ke všem požadovaným sloupcům najednou.
Shrnuto:
- Parquet používá sloupcovou strukturu pro ukládání dat.
- Jedná se o optimalizovaný formát pro hromadné ukládání složitých dat v úložných systémech.
- Parquet zahrnuje různé metody pro kompresi a kódování dat.
- Výrazně snižuje dobu skenování dat a dotazování a zabírá méně místa na disku než jiné formáty, jako je CSV.
- Minimalizuje počet I/O operací, snižuje náklady na ukládání dat a provádění dotazů.
- Obsahuje metadata, která usnadňují vyhledávání dat.
- Poskytuje podporu open source.
Jak jsou data uložena v Parquet
Pojďme se podívat, jak jsou data uložena ve formátu Parquet:
V jednom souboru může být více horizontálních oddílů, které se nazývají skupiny řádků. Každá skupina řádků se dále dělí vertikálně. Sloupce jsou rozděleny do několika částí. Data jsou uložena jako stránky uvnitř bloků sloupců. Každá stránka obsahuje zakódované datové hodnoty a metadata. Jak již bylo zmíněno, metadata celého souboru jsou uložena v zápatí souboru na úrovni skupiny řádků.
Vzhledem k tomu, že jsou data rozdělena do sloupcových částí, je snadné přidávat nová data kódováním nových hodnot do nového bloku a souboru. Metadata jsou následně aktualizována. Parquet je tedy velmi flexibilní formát.
Parquet nativně podporuje kompresi dat pomocí technik komprese stránek a slovníkového kódování. Ukažme si jednoduchý příklad slovníkové komprese:
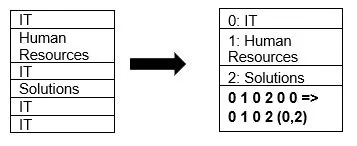
Ve výše uvedeném příkladu vidíme oddělení IT opakovaně. Při ukládání do slovníku formát zakóduje data snadno uložitelnou hodnotou (0,1,2…) spolu s počtem opakování – například IT, IT se změní na 0,2, což šetří místo. Dotazování na komprimovaná data je rychlejší.
Porovnání CSV a Parquet
Nyní, když máme představu o formátech CSV a Parquet, podívejme se na jejich srovnání:
| CSV | Parquet |
| Formát úložiště založený na řádcích. | Hybridní formát úložiště, kombinující řádky a sloupce. |
| Zabírá hodně místa, protože nemá výchozí kompresi. Například 1 TB soubor zabere stejné místo v Amazon S3 nebo jiném cloudu. | Při ukládání komprimuje data, takže zabírá méně místa. 1 TB soubor v Parquet zabere například pouze 130 GB místa. |
| Doba dotazu je pomalá, protože pro každý sloupec se musí načíst každý řádek. | Doba dotazu je 34x rychlejší díky sloupcovému ukládání a přítomnosti metadat. |
| Pro jeden dotaz je potřeba naskenovat více dat. | Při provádění dotazu se skenuje o 99% méně dat, což optimalizuje výkon. |
| Většina úložišť účtuje poplatky podle prostoru, takže CSV znamená vysoké náklady. | Nižší náklady na úložiště, protože data jsou uložena v komprimovaném a kódovaném formátu. |
| Schéma souboru se musí buď odvodit (což vede k chybám), nebo dodat (zdlouhavé). | Schéma souboru je uloženo v metadatech. |
| Formát je vhodný pro jednoduché datové typy. | Parquet je vhodný i pro složité datové typy, jako jsou vnořená schémata, pole a slovníky. |
Závěr
Na příkladech jsme si ukázali, že Parquet je efektivnější než CSV z hlediska nákladů, flexibility a výkonu. Je to efektivní mechanismus pro ukládání a získávání dat, zvláště v dnešní době cloudového úložiště a optimalizace prostoru. Všechny hlavní platformy, jako Azure, AWS a BigQuery, podporují formát Parquet.
