Úvod do Promethea a Grafana
Prometheus je open-source systém pro monitorování, který se zaměřuje na metriky. Jeho princip spočívá ve sběru dat ze služeb a hostitelů pomocí HTTP požadavků na speciální koncové body metrik. Shromážděné informace se následně ukládají do databáze časových řad, což umožňuje jejich analýzu a využití pro generování upozornění.
Proč je monitorování důležité?
- Umožňuje včasné varování před potenciálními problémy, ideálně ještě předtím, než k nim dojde, což dává čas na jejich řešení.
- Poskytuje jasný přehled o stavu systému, což usnadňuje analýzu, ladění a efektivní odstraňování chyb.
- Díky monitorování lze sledovat trendy a změny v čase, například počet aktivních relací v daném okamžiku, což pomáhá při rozhodování o návrhu a plánování kapacit.
Monitorování se typicky zaměřuje na události, jako je zpracování HTTP požadavku, odeslání odpovědi, čtení z disku nebo přihlášení uživatele. Širší monitorování systému zahrnuje profilování, logování, sledování, metriky, upozornění a vizualizaci.
Blackbox vs. Whitebox monitorování
Monitorování lze rozdělit do dvou hlavních kategorií:
Blackbox monitorování
Při monitorování typu blackbox sledujeme aplikaci nebo hostitele z vnější perspektivy. To může být z hlediska detailů poměrně omezující.
Whitebox monitorování
Naopak, whitebox monitorování umožňuje nahlédnout do vnitřních mechanismů služby. Poskytuje detailní data o stavu a výkonu interních komponent.
Čtyři klíčové metriky
Podle společnosti Google, pokud bychom měli měřit pouze čtyři metriky našeho uživatelského systému, měly by to být tyto čtyři, často označované jako čtyři zlaté signály:
#1. Latence
Doba potřebná ke zpracování požadavku, ať už úspěšného nebo neúspěšného. Důležité je sledovat obě kategorie.
#2. Provoz
Míra zátěže, které je systém vystaven. U webové služby to typicky znamená počet HTTP požadavků za sekundu.
#3. Chyby
Počet neúspěšných požadavků.
#4. Nasycení
Úroveň zaplnění vašich služeb. Zvýšení latence je často silným indikátorem nasycení. Mnohé systémy začínají vykazovat snížený výkon dříve, než dosáhnou 100% využití.
Typy metrik v Prometheu
Prometheus pracuje se čtyřmi základními typy metrik:
#1. Čítač (Counter)
Hodnota čítače se vždy zvyšuje, nikdy nesnižuje (může být resetována na nulu). Pokud se načtení dat nezdaří, pouze se ztratí jeden datový bod, kumulativní nárůst bude k dispozici při dalším čtení. Příklady:
- Celkový počet přijatých HTTP požadavků
- Počet výjimek
#2. Měřidlo (Gauge)
Měřidlo představuje aktuální stav v konkrétním čase a jeho hodnota se může jak zvyšovat, tak snižovat. Pokud dojde k chybě při načítání dat, daný vzorek se ztratí a další načtení může ukázat odlišnou hodnotu. Příklady: volné místo na disku, využití paměti.
#3. Histogram
Histogram vzorkuje pozorování a rozděluje je do konfigurovatelných segmentů. Používá se například pro sledování trvání požadavku nebo velikosti odpovědí. Můžeme například měřit dobu trvání konkrétního HTTP požadavku. Histogram bude mít definovanou sadu segmentů, například 1 ms, 10 ms a 25 ms. Prometheus nebude ukládat každou dobu trvání zvlášť, ale frekvenci požadavků, které spadají do konkrétních segmentů.
#4. Souhrn (Summary)
Souhrn funguje podobně jako histogram, vzorkuje pozorování a používá se typicky pro trvání nebo velikost odpovědí. Poskytuje celkový počet pozorování a součet všech pozorovaných hodnot, což umožňuje vypočítat průměrnou hodnotu. Například, pokud během jedné minuty byly tři požadavky s dobou trvání 2, 3 a 4 sekundy, součet bude 9, počet 3, a průměrná latence 3 sekundy.
Komponenty ekosystému Prometheus
Prometheus Server
Shromažďuje metriky, ukládá je do databáze a zpřístupňuje je pro dotazování. Na základě shromážděných metrik odesílá upozornění.
Scraping
Prometheus je systém založený na principu stahování metrik. K načtení metrik používá HTTP požadavky, tzv. "scrape". Tyto požadavky odesílá na cíle definované v konfiguraci.
Každý cíl (staticky definovaný nebo dynamicky objevený) je "scrapován" v pravidelných intervalech (interval scrapování). Během každého scrapu se načítá HTTP koncový bod /metrics, aby se získal aktuální stav klientských metrik, které jsou následně ukládány do databáze časových řad Prometheus.
Existuje více databází časových řad vhodných pro monitorování, které stojí za zvážení.
Klientské knihovny
Pro monitorování služby je nutné přidat instrumentaci do kódu. Existují klientské knihovny pro všechny populární programovací jazyky a runtime prostředí. Použitím těchto knihoven lze pomocí několika řádků kódu začít vydávat metriky. Tomu se říká přímá instrumentace. Knihovny umožňují definovat interní metriky a zpřístupnit je pomocí HTTP koncového bodu. Při scrapování koncového bodu /metrics, klientská knihovna odešle metriky na server.
Prometheus oficiálně nabízí klientské knihovny pro Go, Javu, Python a Ruby. Díky otevřenému ekosystému jsou k dispozici i komunitní knihovny pro C, PHP, Node.js, C#/.NET a mnoho dalších.
Exportery
Některé aplikace poskytují metriky v jiném formátu, než jaký očekává Prometheus. Pro tyto případy, a také pro aplikace, ke kterým nemáme přímý přístup ke kódu, nelze přidávat instrumentaci přímo. Jde například o servery MySQL, Kafka, JMX, HAProxy a NGINX. V takových scénářích se využívají exportery.
Exporter je nástroj, který se nasazuje spolu s aplikací, kterou chceme monitorovat. Exporter funguje jako proxy mezi aplikací a Prometheem. Přijímá požadavky od serveru Prometheus, shromažďuje data z přístupových protokolů, chybových protokolů aplikace, transformuje je do správného formátu a následně je vrací na server Prometheus.
Mezi oblíbené exportery patří:
- Windows – pro metriky serverů Windows
- Node – pro metriky serverů Linux
- Blackbox – pro metriky výkonu DNS a webových stránek
- JMX – pro metriky aplikací založených na Javě
Po instrumentaci aplikací nebo nasazení exporterů je potřeba informovat Prometheus o jejich umístění. To lze provést pomocí statické konfigurace. V dynamických prostředích to není možné, proto se využívá objevování služeb (service discovery).
Upozorňování (Alerting)
Upozorňování v Prometheu se skládá ze dvou hlavních částí:
Pravidla pro upozorňování (alerting rules) odesílají upozornění do Alertmanageru.
Alertmanager spravuje přijaté výstrahy. Odesílá upozornění pomocí mnoha předdefinovaných integrací, jako jsou e-mail, Slack, Hipchat a PagerDuty. Alertmanager může také provádět ztišení (silencing) nebo agregaci, aby se snížil počet notifikací.
Zde je průvodce monitorováním linuxového serveru pomocí Prometheus a Dashboard.
Vizualizace pomocí řídicích panelů
Prometheus nabízí API, která umožňují generovat surová data pomocí dotazů PromQL pro vizualizaci.
I když Prometheus obsahuje prohlížeč výrazů pro ad-hoc dotazy, nejlepším dostupným nástrojem pro vizualizaci je Grafana. Grafana se plně integruje s Prometheem a umožňuje vytvářet širokou škálu přehledných dashboardů.
Je nutné nastavit Prometheus jako zdroj dat pro Grafanu.
Panely lze do dashboardů přidávat:
- Importem panelů vytvořených komunitou
- Vytvořením vlastních panelů
- Použitím předdefinovaných panelů.
Ukázka předdefinovaného panelu pro node exporter:
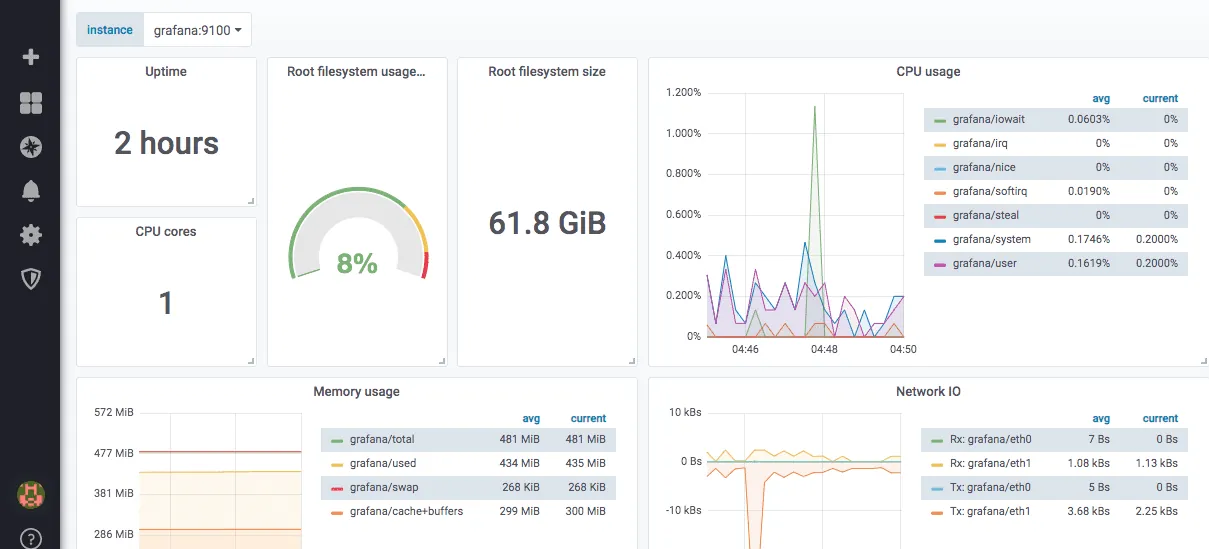
Grafana také nabízí modul WorldPing, který umožňuje sledovat metriky výkonu webu a DNS po celém světě.
Shrnutí
Prometheus má nízké nároky na zdroje. Jeho spuštění je poměrně jednoduché, protože se jedná o jediný binární soubor s konfiguračním souborem. Dokáže zpracovat tisíce cílů a pohltit miliony vzorků za sekundu. Prometheus je navržen pro monitorování celkového stavu a chování systému.
Grafana je ideální nástroj pro vizualizaci metrik a bezproblémově se integruje s Prometheem.
