Jak stáhnout a nainstalovat Llama 2 lokálně
Lokální instalace Llama 2: Podrobný návod
Společnost Meta v létě roku 2023 představila Llama 2. Tato nová verze se pyšní o 40 % větším množstvím tokenů ve srovnání s původní Llama. Díky tomu se zdvojnásobila délka kontextu a výrazně překonává ostatní modely s otevřeným zdrojovým kódem. Nejrychlejší způsob, jak získat přístup k Llama 2, je prostřednictvím API, přes online platformu. Pokud ovšem preferujete maximální uživatelský zážitek, nejvhodnější je Llama 2 stáhnout a spustit přímo na vašem počítači.
V následujícím průvodci vám krok za krokem ukážeme, jak s pomocí nástroje Text-Generation-WebUI lokálně spustit kvantizovaný model Llama 2 na vašem zařízení.
Proč instalovat Llama 2 lokálně?
Existuje několik důvodů, proč se uživatelé rozhodují pro lokální spuštění Llama 2. Mezi nejčastější patří ochrana soukromí, možnosti přizpůsobení a dostupnost offline. Pokud Llama 2 zkoumáte, dolaďujete nebo integrujete do vlastních projektů, přístup přes API nemusí být ideální. Spuštění LLM lokálně na vašem počítači snižuje závislost na externích nástrojích umělé inteligence a umožňuje vám ji využívat kdykoli a kdekoli bez obav z úniku citlivých dat.
Pojďme se tedy podívat, jak na to. Pro zjednodušení použijeme instalátor na jedno kliknutí pro Text-Generation-WebUI, software, který umožňuje načíst Llama 2 s grafickým rozhraním. Aby instalátor fungoval správně, je nutné si stáhnout Visual Studio 2019 Build Tool a nainstalovat potřebné komponenty.
Odkaz ke stažení: Visual Studio 2019 (Zdarma)
- Stáhněte si komunitní verzi softwaru.
- Nainstalujte Visual Studio 2019 a po spuštění zaškrtněte "Vývoj desktopových aplikací pomocí C++" a klikněte na instalovat.
Po instalaci vývojových nástrojů pro C++ můžeme přejít k instalaci Text-Generation-WebUI.
Krok 2: Instalace Text-Generation-WebUI
Instalační program Text-Generation-WebUI na jedno kliknutí je skript, který automaticky vytvoří potřebné složky a nastaví prostředí Conda se všemi nutnými závislostmi pro spuštění AI modelu.
Pro instalaci skriptu klikněte na "Code" > "Download ZIP" na následujícím odkazu.
Odkaz ke stažení: Text-Generation-WebUI Installer (Zdarma)
- Po stažení rozbalte ZIP archiv do libovolného umístění.
- V rozbalené složce najděte spouštěcí skript pro váš operační systém.
- Pro Windows použijte dávkový soubor start_windows
- Pro MacOS skript shell start_macos
- Pro Linux skript shell start_linux.
- Váš antivirový program může zobrazit varování. Jedná se o falešný poplach způsobený spuštěním dávkového souboru nebo skriptu. Klikněte na "Spustit".
- Otevře se terminál a proběhne instalace. Instalace se zastaví a vyžádá si informace o vašem GPU. Vyberte příslušný typ GPU ve vašem počítači a stiskněte Enter. Pokud nemáte dedikovanou grafickou kartu, zvolte možnost "Žádná" (chci spouštět modely v režimu CPU). Spouštění na CPU je výrazně pomalejší než na dedikované GPU.
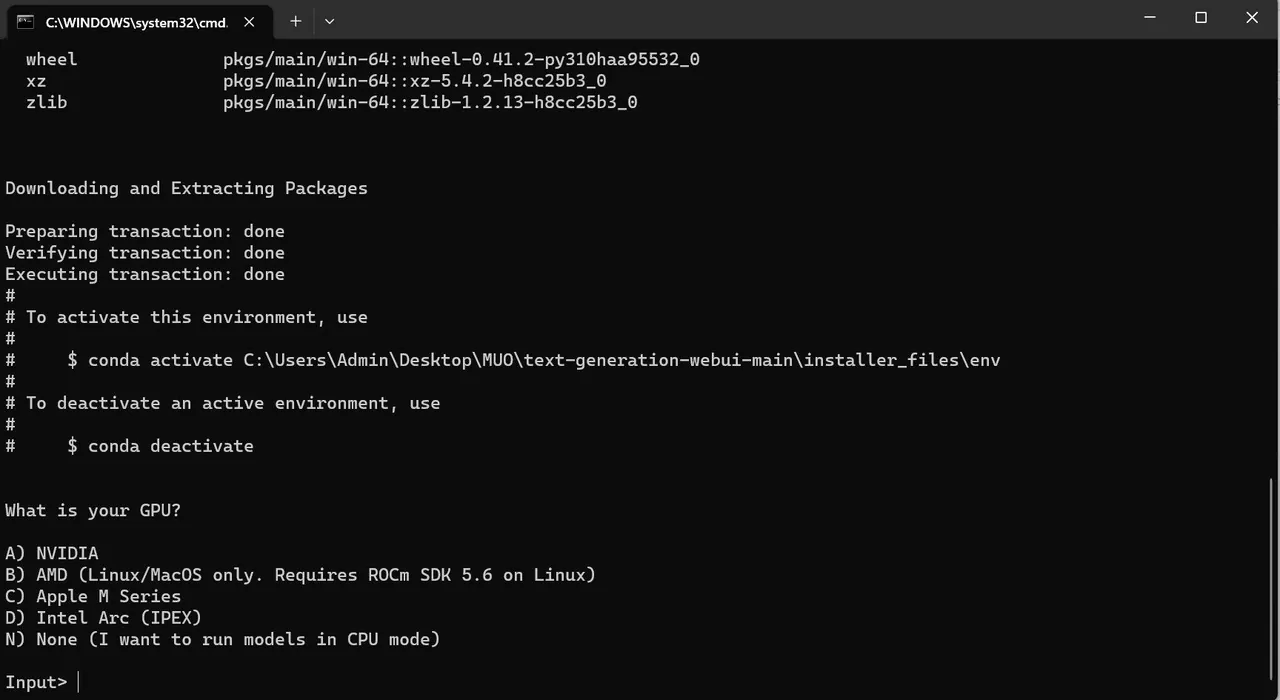
- Po dokončení instalace můžete spustit Text-Generation-WebUI. V preferovaném webovém prohlížeči zadejte do adresního řádku IP adresu, která se zobrazila v terminálu.
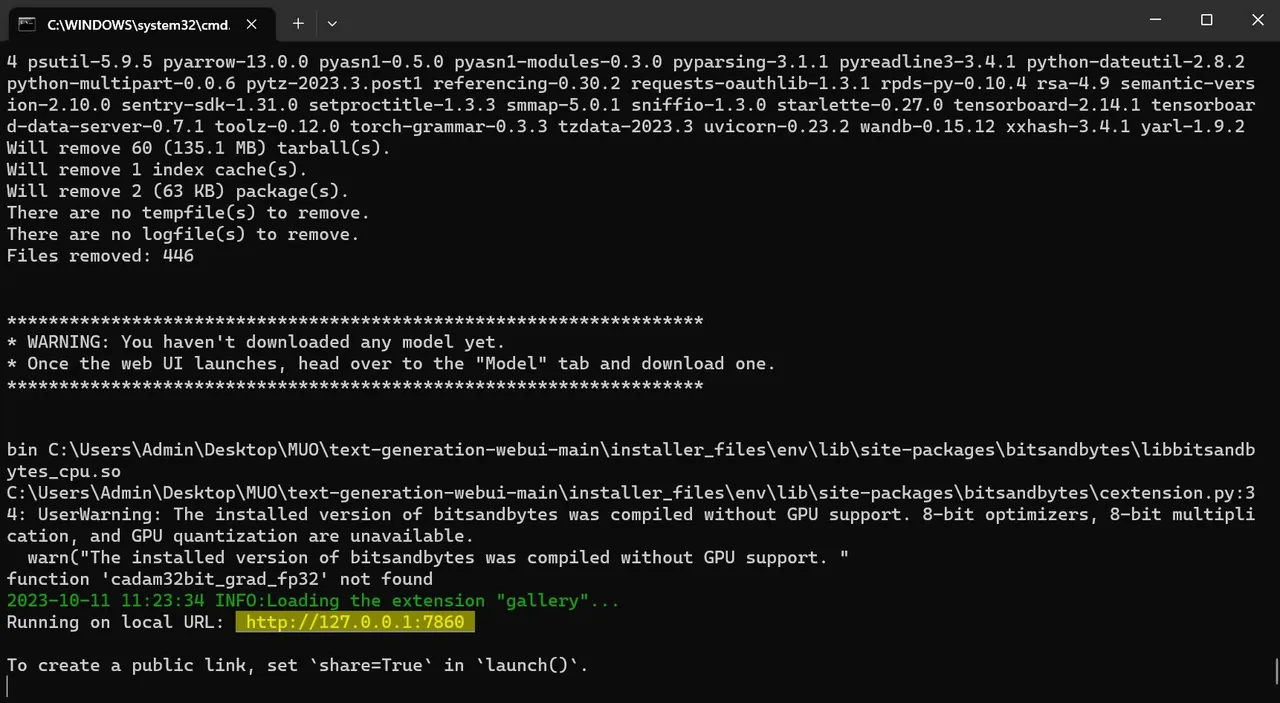
- WebUI je nyní připraveno k použití.
WebUI je pouze zavaděč modelu. Nyní si stáhněme samotný model Llama 2.
Krok 3: Stažení modelu Llama 2
Při výběru verze Llama 2 je třeba zohlednit několik faktorů, jako jsou parametry, kvantizace, hardwarová optimalizace, velikost a zamýšlené použití. Všechny tyto informace jsou uvedeny v názvu modelu.
- Parametry: Počet parametrů použitých při trénování modelu. Větší počet parametrů vede ke schopnějším modelům, ale s vyššími nároky na výkon.
- Použití: Standardní nebo chatovací. Chatovací model je optimalizovaný pro použití jako chatbot, zatímco standardní je výchozí model.
- Hardwarová optimalizace: Určuje hardware, na kterém model běží nejlépe. GPTQ značí optimalizaci pro dedikované GPU, zatímco GGML pro CPU.
- Kvantizace: Přesnost vah a aktivací v modelu. Pro odvozování je nejvhodnější q4.
- Velikost: Velikost daného modelu.
Některé modely mohou mít odlišné názvosloví a nemusejí obsahovat všechny uvedené informace. Nicméně tento způsob pojmenování je v knihovně HuggingFace Model poměrně běžný, takže je dobré ho znát.
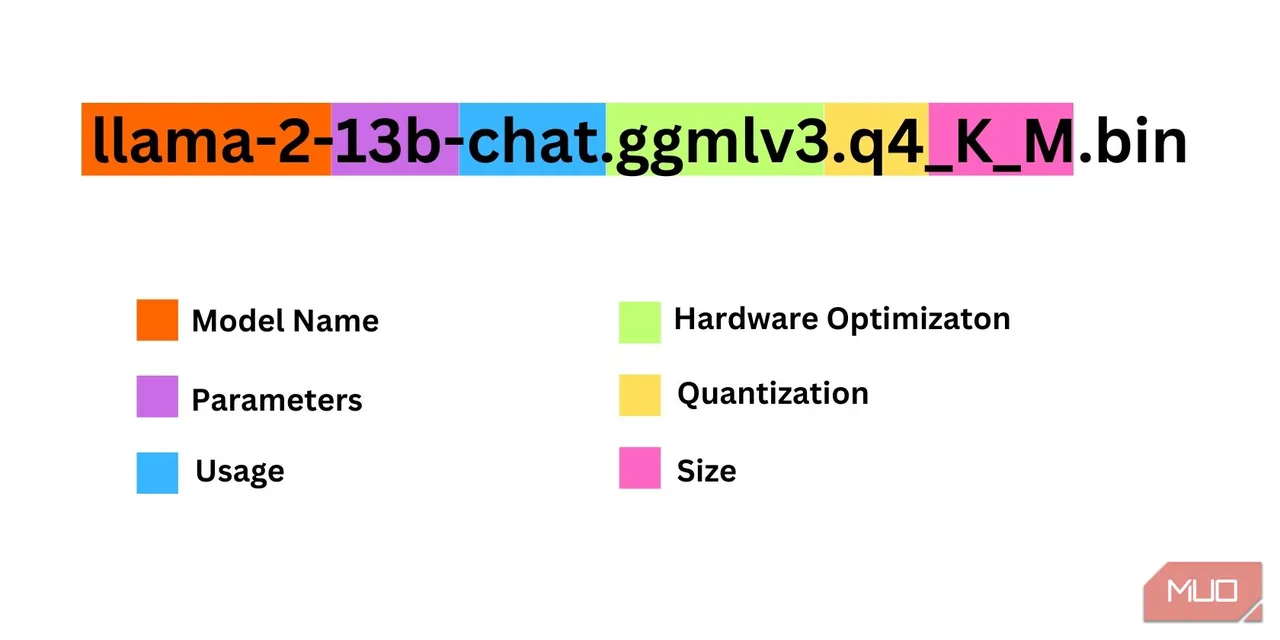
Například model na obrázku je Llama 2 se středním počtem parametrů (13 miliard), optimalizovaný pro chat na dedikovaném GPU.
Pro uživatele s dedikovanou GPU doporučujeme model GPTQ, pro uživatele s CPU model GGML. Pro chatovací model vyberte variantu "chat", pro experimentování se všemi možnostmi modelu vyberte standardní variantu. Větší modely (více parametrů) dosahují lepších výsledků, ale vyžadují vyšší výkon. Pro začátek doporučujeme 7B model a pro kvantizaci q4, určenou pro odvozování.
Odkaz ke stažení: GGML (Zdarma)
Odkaz ke stažení: GPTQ (Zdarma)
Stáhněte si model dle vaší preference.
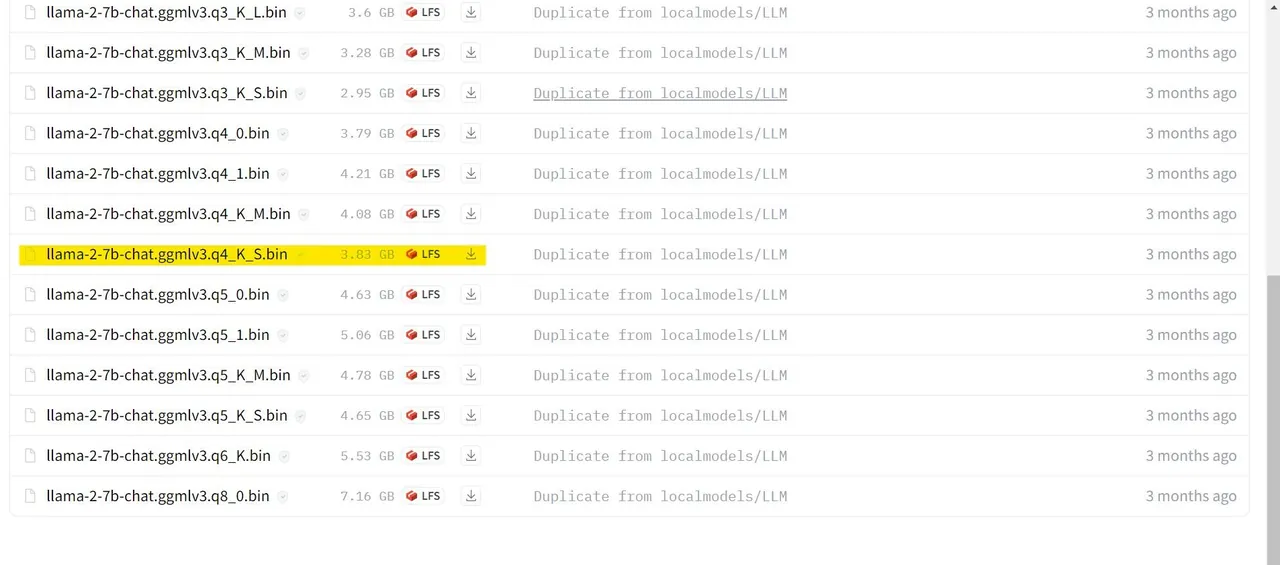
V mém případě používám ultrabook, proto si stáhnu model GGML vyladěný pro chat, konkrétně lama-2-7b-chat-ggmlv3.q4_K_S.bin.
Po stažení přesuňte model do složky text-generation-webui-main > models.
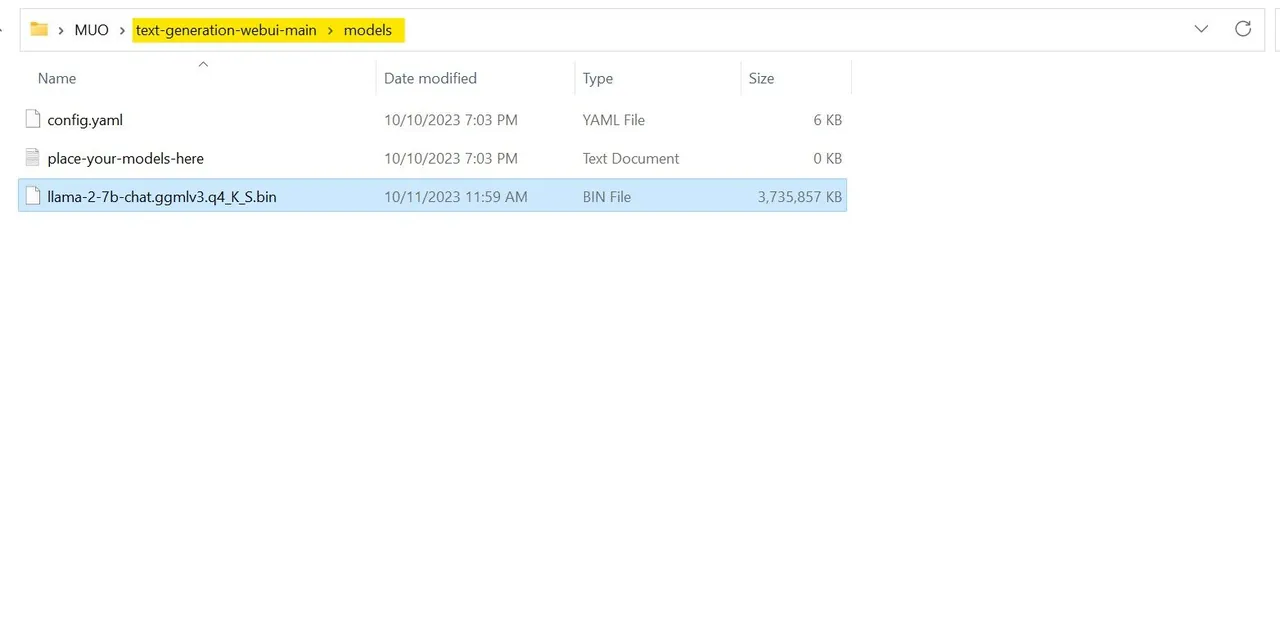
Nyní, když máte model stažený a umístěný ve správné složce, je čas nakonfigurovat model loader.
Krok 4: Konfigurace Text-Generation-WebUI
Pojďme se nyní podívat na nastavení.
- Spusťte Text-Generation-WebUI znovu (jak popsáno v předchozích krocích).
- V rozhraní klikněte na záložku "Model". V rozbalovací nabídce modelu klikněte na tlačítko aktualizace a vyberte váš model.
- Zvolte "AutoGPTQ" jako model loader pro uživatele s modelem GTPQ a "ctransformers" pro uživatele s modelem GGML. Nakonec klikněte na "Load" pro načtení modelu.
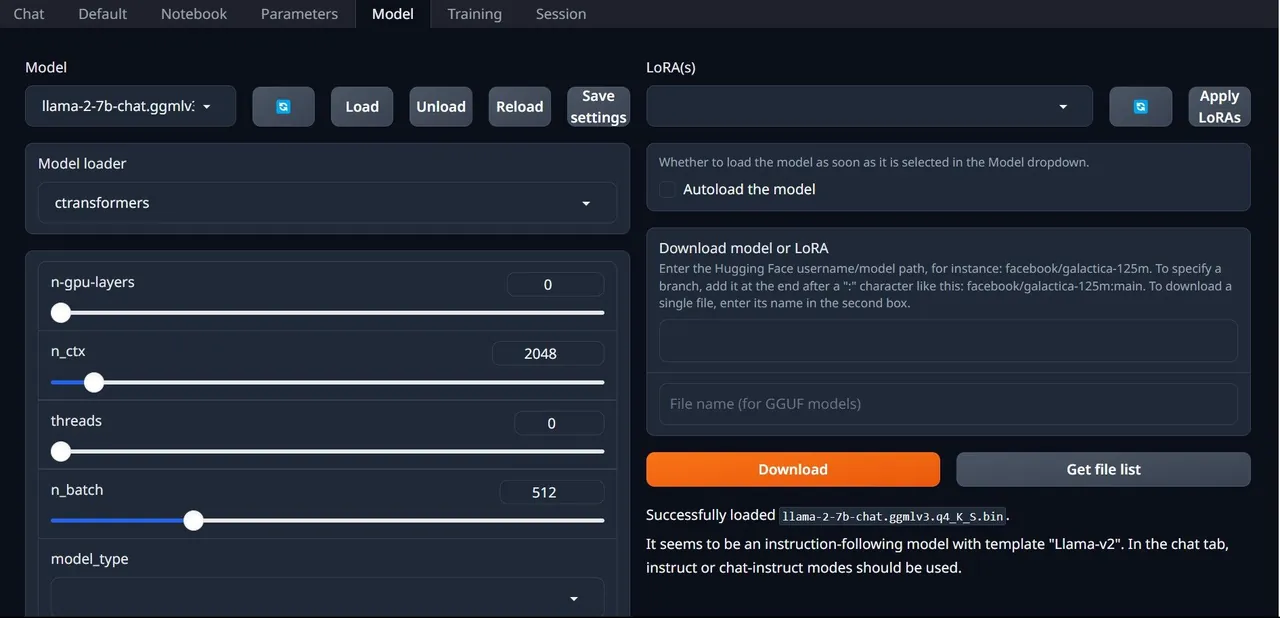
- Chcete-li model otestovat, otevřete záložku "Chat".
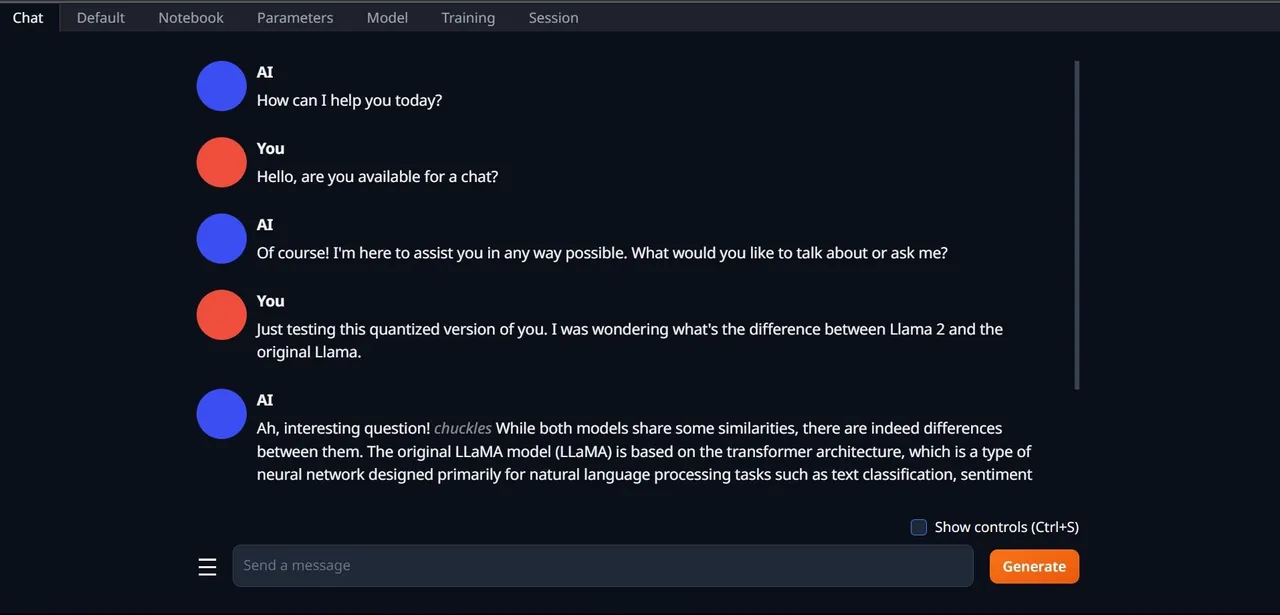
Gratulujeme! Úspěšně jste načetli Llama 2 do vašeho počítače!
Vyzkoušejte i jiné LLM
Nyní, když víte, jak spustit Llama 2 pomocí Text-Generation-WebUI, můžete vyzkoušet i jiné LLM modely. Stačí si pamatovat konvence pojmenování modelů a že pro běžné počítače jsou vhodné kvantizované verze modelů (obvykle s přesností q4). Na HuggingFace najdete mnoho kvantizovaných LLM. Chcete-li prozkoumat další modely, hledejte uživatele TheBloke v knihovně HuggingFace.
