Přátelský úvod do analýzy dat v Pythonu
V posledních letech se význam Pythonu v oblasti datové vědy rapidně zvýšil a jeho popularita neustále roste.
Datová věda je rozsáhlá a zahrnuje mnoho specializovaných disciplín. Jednou z klíčových je analýza dat, jejíž pochopení je zásadní bez ohledu na úroveň vašich dovedností v datové vědě.
Co je analýza dat?
Analýza dat spočívá v čištění a transformaci velkého objemu nestrukturovaných informací s cílem získat relevantní poznatky a informace. Tyto poznatky následně slouží jako podklad pro informovaná rozhodnutí.
K analýze dat se používají různé nástroje, jako například Python, Microsoft Excel, Tableau nebo SaS. V tomto článku se však zaměříme na to, jak se provádí analýza dat v Pythonu, konkrétně s využitím knihovny Pandas.
Co je to Pandas?
Pandas je open-source knihovna Pythonu, která se používá pro manipulaci a zpracování dat. Je vysoce efektivní, rychlá a nabízí nástroje pro načítání různých typů dat do paměti. Data lze pomocí Pandas transformovat, filtrovat, indexovat nebo i seskupovat.
Datové struktury v Pandas
Pandas používá tři základní datové struktury:
- Série (Series)
- DataFrame
- Panel
Nejlépe si tyto struktury představíme tak, že jedna obsahuje více instancí té předchozí. DataFrame je tedy složen z několika sérií a Panel z více datových rámců.
Série představuje jednorozměrné pole.
DataFrame je dvourozměrná struktura tvořená několika sériemi.
Panel je trojrozměrná struktura skládající se z několika DataFrames.
Nejčastěji budeme pracovat s dvourozměrným DataFrame, který se často používá pro reprezentaci datových sad.
Analýza dat v Pandas
Pro potřeby tohoto článku není nutná žádná instalace. Využijeme Colab od Googlu, což je online prostředí Pythonu pro analýzu dat, strojové učení a umělou inteligenci. Jedná se o cloudový Jupyter Notebook, který obsahuje předinstalované balíčky Pythonu, které datový vědec potřebuje.
Přejděte na https://colab.research.google.com/notebooks/intro.ipynb. Měla by se zobrazit následující stránka.
V levém horním rohu klikněte na „Soubor“ a vyberte „Nový zápisník“. Otevře se nová stránka s Jupyter Notebook. Prvním krokem je import knihovny Pandas do našeho pracovního prostředí, což se provede spuštěním následujícího kódu:
import pandas as pd
Pro tento článek použijeme datový soubor s informacemi o cenách nemovitostí. Tento soubor naleznete zde. Nejdříve si datovou sadu načteme do našeho prostředí.
To se provede spuštěním následujícího kódu v nové buňce:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0', sep=',')
Funkce .read_csv() se používá pro načítání souborů CSV a vlastnost sep udává, že data jsou oddělená čárkami.
Načtený soubor CSV je uložen v proměnné df.
V Jupyter Notebooku není nutné používat funkci print(). Stačí zadat název proměnné a Jupyter Notebook ji vypíše.
Vyzkoušejte zadat df do nové buňky a spusťte ji. Zobrazí se všechna data z naší datové sady jako DataFrame.
Ne vždy chceme vidět všechna data. Často nás zajímá jen několik prvních řádků a názvy sloupců. Pro zobrazení prvních pěti řádků se používá funkce df.head() a pro zobrazení posledních pěti řádků df.tail(). Výstup z jedné z těchto funkcí by vypadal následovně:
Je užitečné zkontrolovat vztahy mezi jednotlivými řádky a sloupci. K tomu slouží funkce .describe().
Spuštěním df.describe() získáme následující výstup:
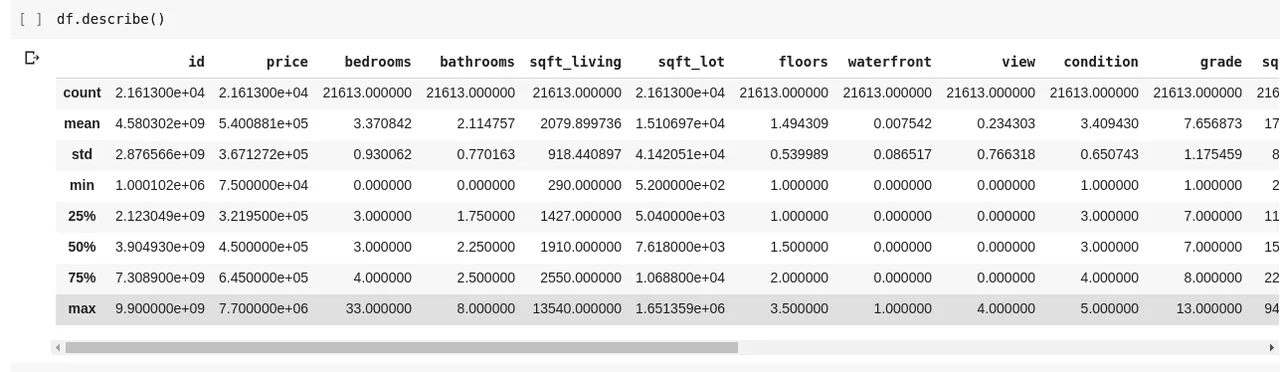
Funkce .describe() poskytuje průměr, směrodatnou odchylku, minimální a maximální hodnoty a percentily pro každý sloupec v DataFrame, což je velmi užitečné.
Můžeme také zjistit tvar našeho 2D DataFrame pomocí df.shape, který vrací n-tici ve formátu (řádky, sloupce).
Názvy všech sloupců v DataFrame můžeme zobrazit pomocí df.columns.
Co když chceme vybrat pouze jeden sloupec a zobrazit všechna data v něm? Použijeme podobný přístup jako při práci se slovníky. Zadejte následující kód do nové buňky a spusťte ho:
df['price ']
Tento kód vrátí sloupec s cenami. Můžeme jej uložit do nové proměnné:
price = df['price']
Nyní můžeme provádět operace na proměnné price, jako by to byl běžný DataFrame. Můžeme například použít df.head(), df.shape atd.
Můžeme vybrat i více sloupců, a to tak, že do df předáme seznam názvů sloupců:
data = df[['price ', 'bedrooms']]
Výše uvedený kód vybere sloupce 'price' a 'bedrooms'. Spuštěním data.head() získáme následující:
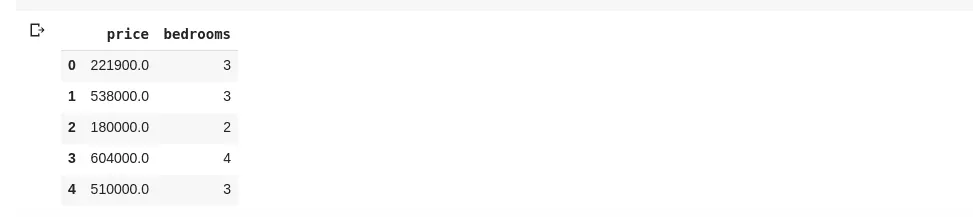
Tento způsob dělení sloupců vrací všechny prvky řádků v daném sloupci. Co když chceme vrátit jen podmnožinu řádků a sloupců? To se dá provést pomocí .iloc, které se indexuje podobně jako seznamy v Pythonu. Například:
df.iloc[50: , 3]
Tento kód vrátí 3. sloupec od 50. řádku až do konce. Stejně jako u krájení seznamů v Pythonu.
Pojďme nyní k zajímavějším věcem. Naše datová sada o cenách nemovitostí obsahuje sloupec s cenou domu a sloupec s počtem ložnic. Cena je spojitá veličina, takže je nepravděpodobné, že bychom našli dva domy se stejnou cenou. Počet ložnic je diskrétní, takže můžeme mít několik domů se dvěma, třemi, čtyřmi ložnicemi atd.
Co když chceme získat všechny domy se stejným počtem ložnic a zjistit průměrnou cenu v každé kategorii? V Pandas je to poměrně snadné:
df.groupby('bedrooms ')['price '].mean()
Výše uvedený kód nejprve seskupí DataFrame podle počtu ložnic pomocí df.groupby(), a poté vybere sloupec ceny a vypočítá průměr pro každou skupinu pomocí .mean().
Co když chceme tyto informace vizualizovat? Chceme zjistit, jak se liší průměrná cena u jednotlivých počtů ložnic. Stačí řetězit předchozí kód s funkcí .plot():
df.groupby('bedrooms ')['price '].mean().plot()
Výsledkem bude následující graf:
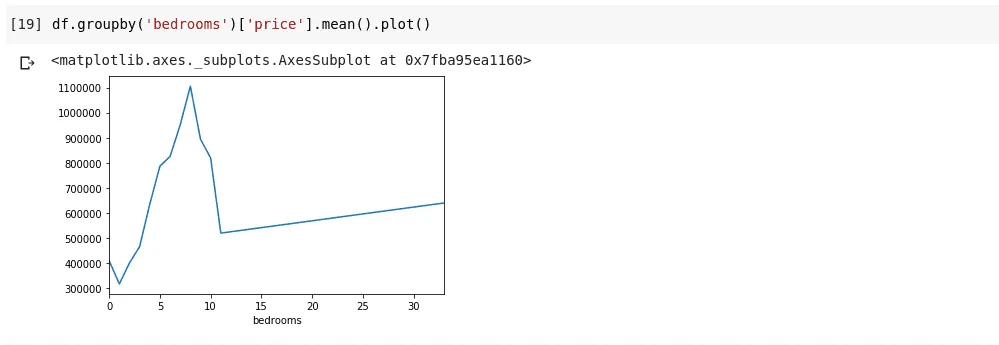
Graf ukazuje trendy v datech. Na vodorovné ose je počet ložnic a na svislé ose průměrná cena. Vidíme, že domy s 5 až 10 ložnicemi jsou výrazně dražší než domy se 3 ložnicemi. Také je zřejmé, že domy s 7 nebo 8 ložnicemi stojí mnohem více než domy s 15, 20 nebo dokonce 30 pokoji.
Právě takové informace ukazují, jak důležitá je analýza dat. Dokážeme z dat extrahovat užitečné poznatky, které bychom bez analýzy nezískali.
Chybějící data
Představte si, že provádíte průzkum, který se skládá z několika otázek. Rozesíláte odkaz na průzkum tisícům lidí, aby mohli poskytnout zpětnou vazbu. Vaším cílem je provést analýzu dat a získat klíčové poznatky.
Může se stát, že někteří lidé se cítí nepříjemně odpovídat na některé otázky a nechají je prázdné. To se nemusí zdát jako problém, ale představte si, že sbíráte číselné údaje a analýza vyžaduje, abyste získali součet, průměr nebo jinou aritmetickou operaci. Několik chybějících hodnot by vedlo k nepřesnostem v analýze. Musíme najít způsob, jak tyto chybějící hodnoty identifikovat a nahradit je hodnotami, které je mohou nahradit.
Pandas nám poskytuje funkci isnull() pro nalezení chybějících hodnot v DataFrame.
Funkci isnull() použijeme následovně:
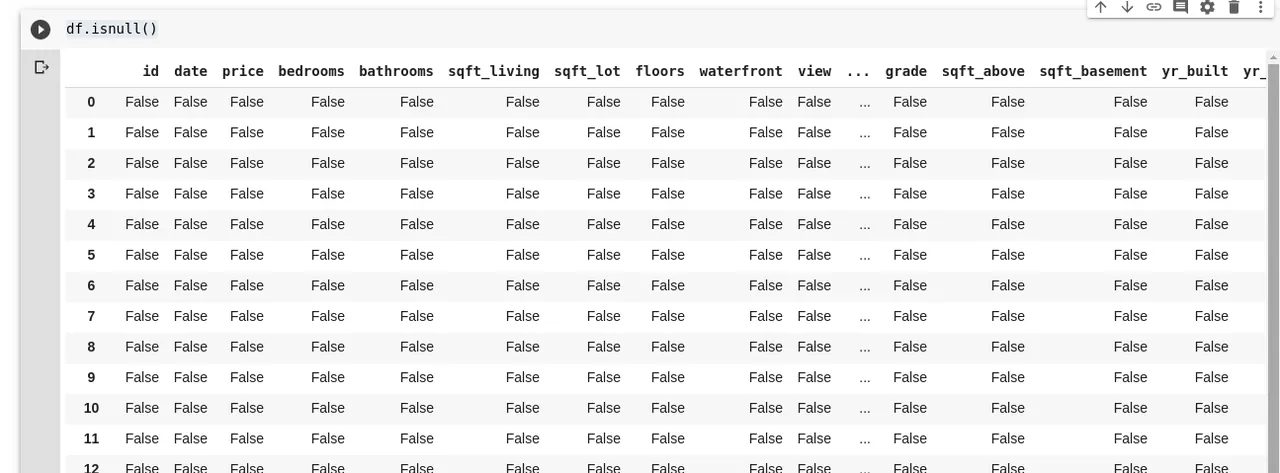
df.isnull()
Tím získáme DataFrame, který nám udává, zda data na daných pozicích chybí či nikoli. Výstup by vypadal takto:
Musíme chybějící hodnoty nahradit. Nejčastěji se používá 0. Někdy se chybějící hodnoty nahrazují průměrem všech hodnot, nebo průměrem hodnot kolem nich. Vše záleží na datovém vědci a použití dat.
Pro vyplnění chybějících hodnot používáme funkci .fillna():
df.fillna(0)
Výše uvedený kód vyplní všechna prázdná místa nulou. Může to být i jakékoli jiné číslo.
Důležitost dat nelze opomenout. Analýza dat se stává klíčem pro digitální ekonomiky.
Všechny příklady z tohoto článku najdete zde.
Pro podrobnější informace se podívejte na online kurz Analýza dat s Pythonem a Pandas.
