Proč jsou malé jazykové modely budoucností umělé inteligence
Zásadní zjištění
- Významné firmy, jako Open AI, Google, Microsoft a Meta, investují do malých jazykových modelů (SLM).
- SLM získávají v oboru na popularitě a jsou považovány za budoucnost umělé inteligence.
- Mezi příklady SLM patří Google Nano, Microsoft Phi-3 a Open AI GPT-4o mini.
Malé jazykové modely (SLM) se stávají klíčovou součástí pokroku v oblasti umělé inteligence. Po vzestupu velkých jazykových modelů (LLM) s příchodem ChatGPT od Open AI, se stále více firem zaměřuje na SLM. Jaké jsou rozdíly mezi těmito modely a proč jsou SLM vnímány jako klíč k budoucnosti AI?
SLM nabývají na důležitosti, ale co přesně to jsou a jak se liší od LLM?
Co je malý jazykový model?
Malý jazykový model (SLM) je typ modelu umělé inteligence s menším počtem parametrů (což si můžeme představit jako hodnoty naučené modelem během tréninku). Podobně jako jejich větší protějšky, SLM umí generovat text a provádět další úlohy. SLM však pro trénink využívají menší datové sady, mají méně parametrů a vyžadují nižší výpočetní výkon pro trénink i provoz.
SLM se soustředí na klíčové funkce a díky své malé velikosti mohou být implementovány na různorodá zařízení, včetně těch bez špičkového hardwaru, jako jsou mobilní telefony. Například Google Nano je SLM navržený od základů pro provoz na mobilních zařízeních. Díky své malé velikosti může Nano fungovat lokálně s připojením k síti i bez něj, jak uvádí společnost.
Kromě Nano existuje mnoho dalších SLM od významných i nových společností v oblasti AI. Mezi populární SLM patří Microsoft Phi-3, OpenAI GPT-4o mini, Anthropic Claude 3 Haiku, Meta Llama 3 a Mixtral 8x7B od Mistral AI.
Existují i další možnosti, které by se daly považovat za LLM, ale ve skutečnosti jde o SLM. To platí zvláště, když většina firem zaujímá mnohostranný přístup tím, že uvádí na trh více než jeden jazykový model ve svém portfoliu, a to jak LLM, tak i SLM. Jedním z příkladů je GPT-4, který má různé modely, včetně GPT-4, GPT-4o (Omni) a GPT-4o mini.
Malé jazykové modely vs. velké jazykové modely
Při diskusi o SLM nelze opomenout jejich velké protějšky: LLM. Hlavní rozdíl mezi SLM a LLM spočívá ve velikosti modelu, která se měří počtem parametrů.
V současné době neexistuje v oboru AI shoda ohledně maximálního počtu parametrů, které by model neměl překročit, aby byl považován za SLM, ani minimálního počtu potřebného pro LLM. Nicméně, SLM mají obvykle miliony až několik miliard parametrů, zatímco LLM mají více, až do bilionů.
Například GPT-3, který byl vydán v roce 2020, má 175 miliard parametrů (a model GPT-4 má údajně kolem 1,76 bilionu), zatímco SLM od Microsoftu Phi-3-mini, Phi-3-small a Phi-3-medium mají 3,8, 7 a 14 miliard parametrů.
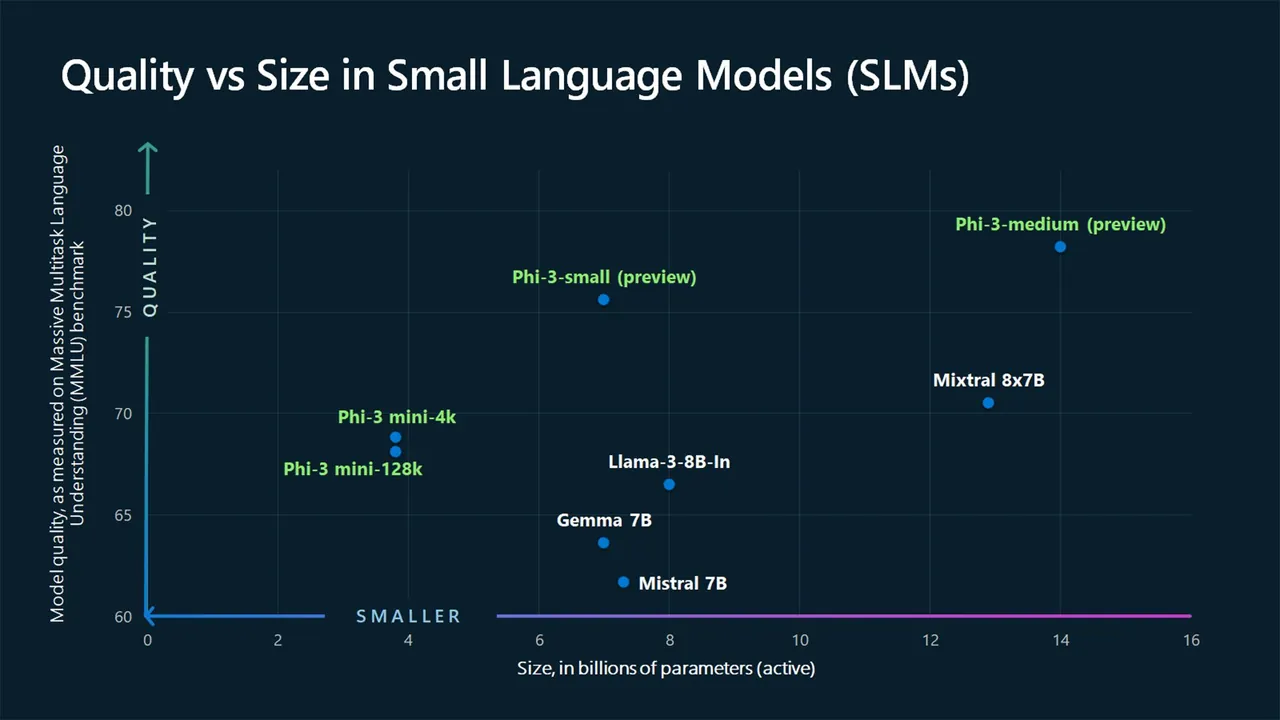
Dalším rozdílem mezi SLM a LLM je množství dat využitých pro trénink. SLM se trénují na menších objemech dat, zatímco LLM používají rozsáhlé datové sady. Tento rozdíl také ovlivňuje schopnost modelu zvládat komplexní úlohy.
Díky velkému množství dat, které se používá při tréninku, jsou LLM lépe uzpůsobeny pro řešení různých typů náročných úkolů vyžadujících pokročilé uvažování, zatímco SLM se lépe hodí pro jednodušší úlohy. Na rozdíl od LLM SLM využívají méně tréninkových dat, ale tato data musí mít vyšší kvalitu, aby bylo dosaženo mnohých schopností LLM v kompaktním balení.
Proč jsou malé jazykové modely budoucností
Pro většinu případů použití jsou SLM vhodnější pro to, aby se staly běžnými modely, které společnosti i spotřebitelé používají k plnění široké škály úkolů. LLM mají jistě své výhody a lépe se hodí pro některé specifické případy, například řešení složitých úkolů. SLM jsou však budoucností pro většinu případů použití z následujících důvodů.
1. Nižší náklady na trénink a údržbu
 Timofeev Vladimir/Shutterstock
Timofeev Vladimir/Shutterstock
SLM potřebují méně dat k tréninku než LLM, což z nich činí nejvhodnější volbu pro jednotlivce i malé a střední firmy s omezenými tréninkovými daty, finančními prostředky nebo obojím. LLM vyžadují velké objemy tréninkových dat, a tím pádem také obrovské výpočetní zdroje pro trénink i provoz.
Pro lepší představu, generální ředitel OpenAI, Sam Altman, potvrdil, že trénink GPT-4 stál přes 100 milionů dolarů, když mluvil na akci MIT (podle Wired). Dalším příkladem je Meta OPT-175B LLM. Meta uvádí, že byl trénován s využitím 992 grafických procesorů NVIDIA A100 80GB, z nichž jeden stojí zhruba 10 000 dolarů, podle CNBC. To dává náklady přibližně 9 milionů dolarů, a to bez dalších nákladů, jako je elektřina, mzdy a podobně.
S takovými čísly není pro malé a střední firmy reálné trénovat LLM. Naproti tomu SLM mají nižší vstupní bariéru z hlediska zdrojů a jsou levnější na provoz, proto je bude využívat stále více společností.
2. Lepší výkon
 GBJSTOCK / Shutterstock
GBJSTOCK / Shutterstock
Výkon je další oblast, ve které SLM díky své kompaktní velikosti překonávají LLM. SLM mají nižší latenci a lépe se hodí pro situace, kdy jsou potřeba rychlejší odezvy, například v reálných aplikacích. Například v systémech hlasové odezvy, jako jsou digitální asistenti, se preferuje rychlá odezva.
Spuštění na zařízení (o tom později) také znamená, že váš požadavek nemusí putovat na online servery a zpět, aby vám byla poskytnuta odpověď, což vede k rychlejším odezvám.
3. Přesnější
 ZinetroN / Shutterstock
ZinetroN / Shutterstock
Pokud jde o generativní AI, jedna věc zůstává konstantní: nekvalitní vstup povede k nekvalitnímu výstupu. Současné LLM byly trénovány s využitím rozsáhlých datových sad z internetu. Proto nemusí být přesné ve všech situacích. To je jeden z problémů s ChatGPT a podobnými modely, a proto byste neměli důvěřovat všemu, co chatbot s AI říká. Na druhou stranu SLM se trénují na podrobnější a kvalitnější data než LLM, a proto vykazují vyšší přesnost.
SLM lze také dále doladit cíleným tréninkem na specifické úlohy nebo domény, což vede k lepší přesnosti v těchto oblastech v porovnání s většími, více generalizovanými modely.
4. Mohou běžet na zařízení
 Pete Hansen/Shutterstock
Pete Hansen/Shutterstock
SLM vyžadují nižší výpočetní výkon než LLM, a proto jsou ideální pro případy edge computingu. Mohou být nasazeny na okrajových zařízeních, jako jsou chytré telefony a autonomní vozidla, která nemají velký výpočetní výkon nebo zdroje. Model Google Nano může běžet na zařízení, což mu umožňuje fungovat i bez aktivního připojení k internetu.
Tato schopnost představuje výhodu pro obě strany, jak pro společnosti, tak pro spotřebitele. Za prvé, je to přínos pro ochranu soukromí, protože uživatelská data se zpracovávají lokálně, namísto aby se odesílala do cloudu, což je důležité, když je AI integrována do našich chytrých telefonů, které obsahují téměř všechny naše osobní údaje. Je to také přínos pro společnosti, protože nepotřebují nasazovat a provozovat rozsáhlé servery pro zpracování úloh AI.
SLM získávají na významu a největší hráči v oboru, jako jsou Open AI, Google, Microsoft, Anthropic a Meta, tyto modely uvádějí na trh. Tyto modely jsou lépe přizpůsobeny pro jednodušší úlohy, které většina z nás s LLM stejně řeší, a proto jsou budoucností.
LLM však nikam nezmizí. Místo toho se budou využívat pro pokročilé aplikace, které kombinují informace z různých oblastí, aby vytvořily něco nového, například v oblasti lékařského výzkumu.
Shrnutí: S rostoucím vývojem a poptávkou po malých jazykových modelech se SLM stávají důležitou součástí naší budoucnosti v oblasti AI, přičemž firmy jako Google, Microsoft a Open AI udávají směr tomuto trendu. Jejich efektivita, nízké náklady na trénink a schopnost bezproblémově fungovat na zařízeních je činí ideálními pro širokou škálu aplikací v moderním světě.
